课程内容链接:https://space.bilibili.com/479141149/channel/collectiondetail?sid=837891
课程实验代码:https://github.com/Ling-Yuchen/compiler-hw
00 - 编译原理概述
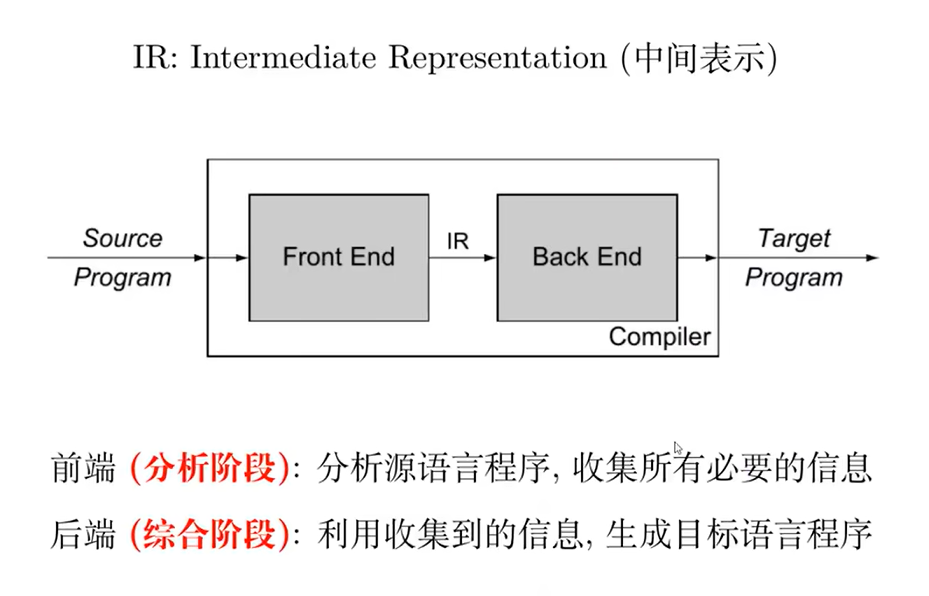
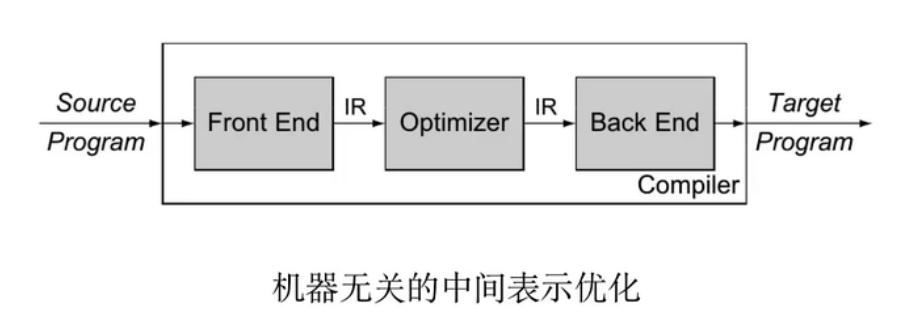
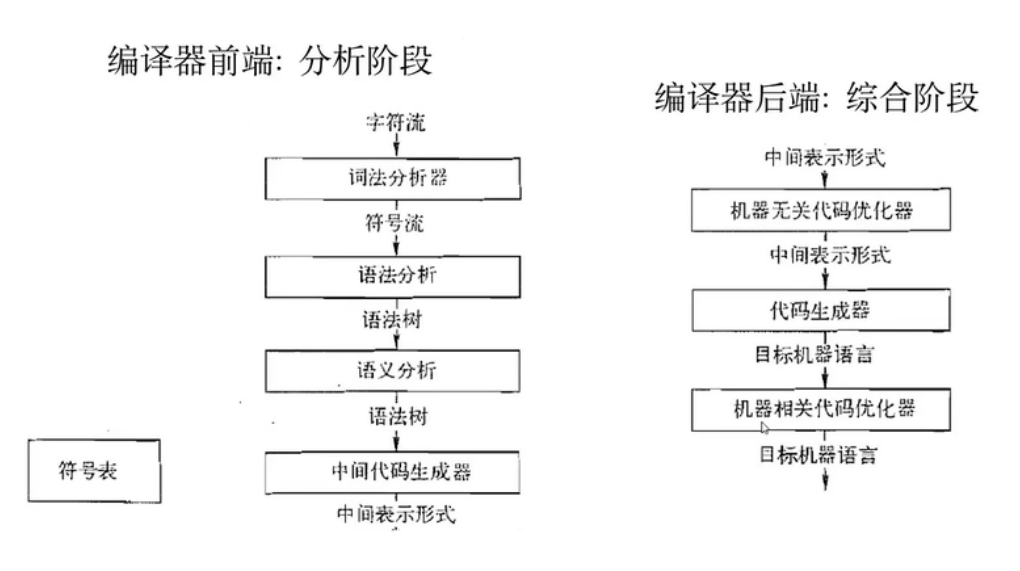


01 - 词法分析器生成器
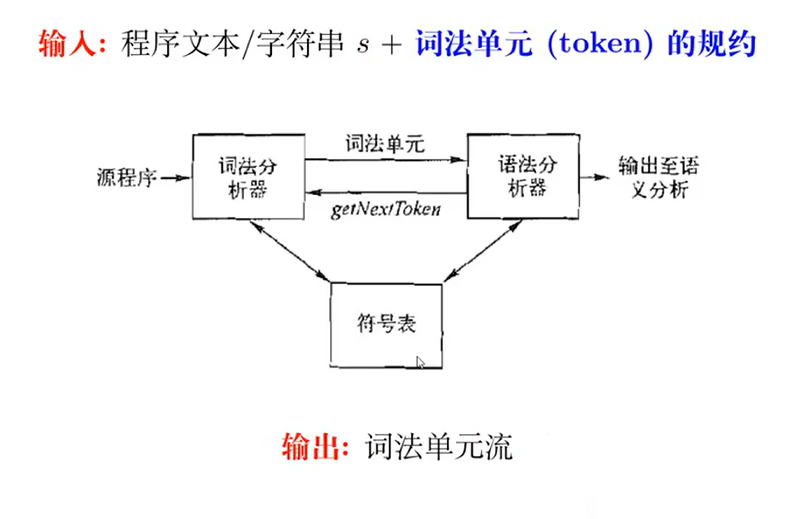
使用 ANTLR 工具编写词法分析器生成器:
- 输入:词法单元的归约
SysYLexer.g4 - 输出:词法分析器
SysYLexer.tokens,SysYLexer.interp,SysYLexer.java
样例:(来自 lab1)
1 | lexer grammar SysYLexer; |
一些定义:





能够在语言(集合)上进行的操作:

正则表达式:


02 - 手写词法分析器
略
03 - 自动机理论与词法分析器生成器
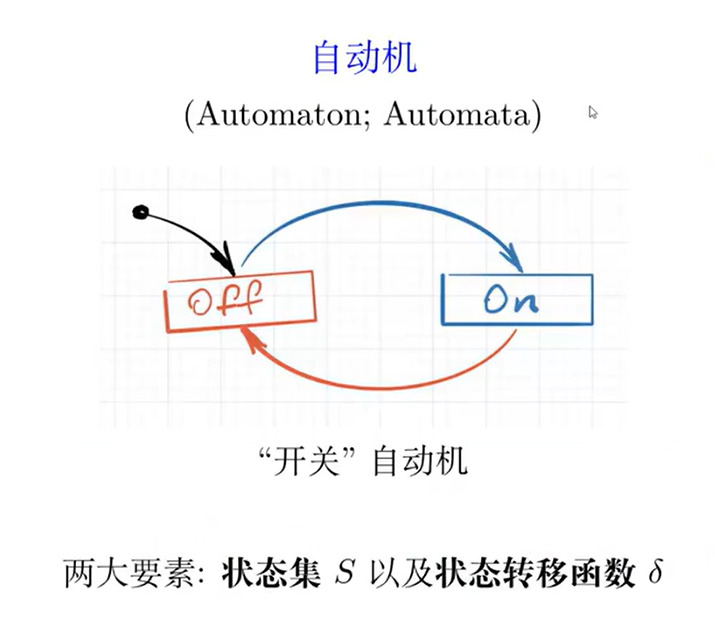
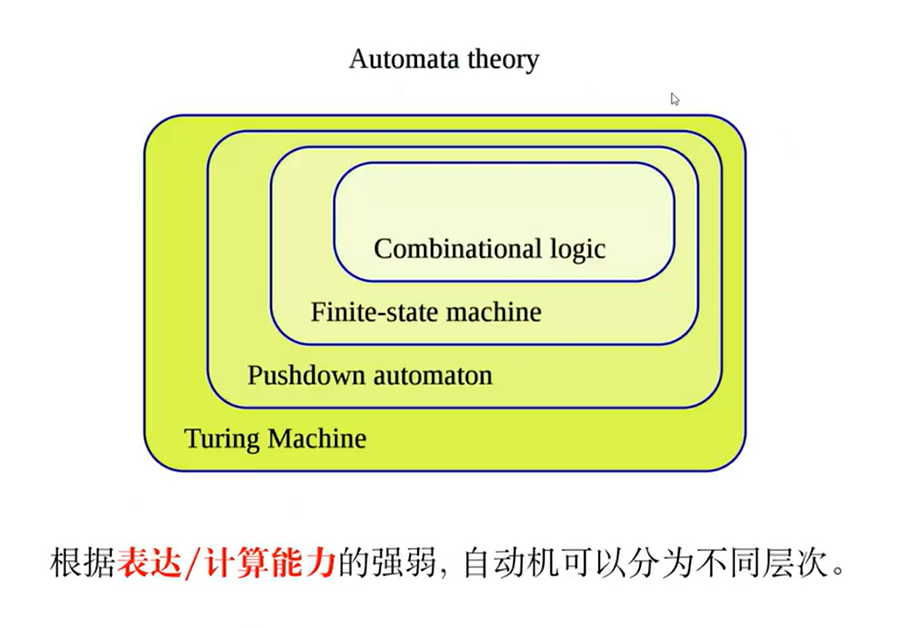
目标:RE to Lexer
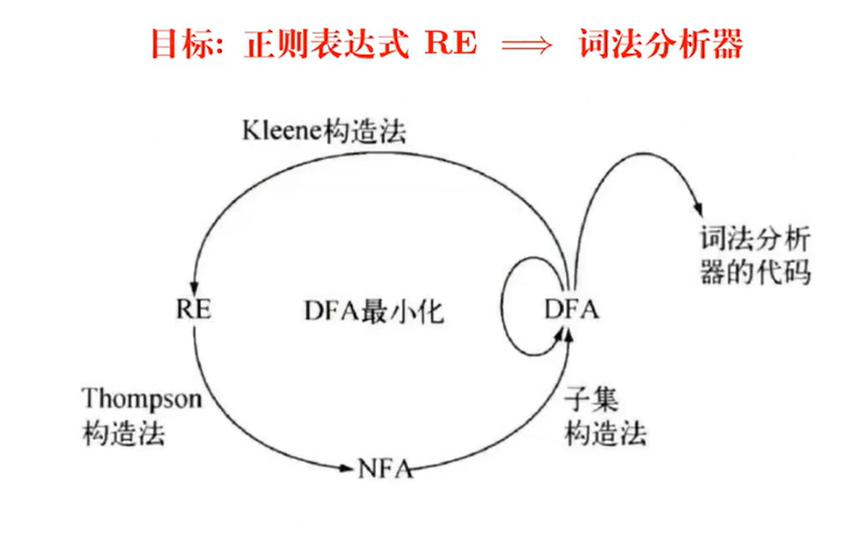
RE:正则表达式
NFA:不确定的有穷自动机(简洁易于理解,便于描述语言 L(A))

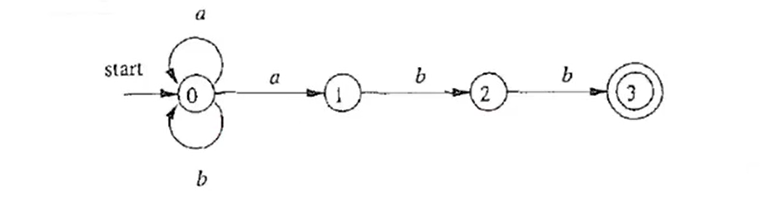
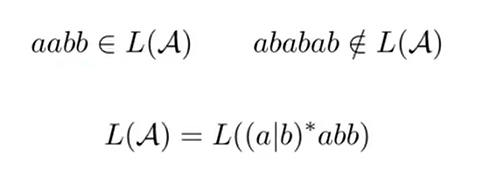
其不确定性在于:
- 在同一状态下,看到相同的字符,可以转移到不同的状态
- 没有看到任何字符(看到 ε),也有可以发生状态的转移

DFA:确定的有穷自动机(易于判断 x ∈ L(A),适合产生词法分析器)

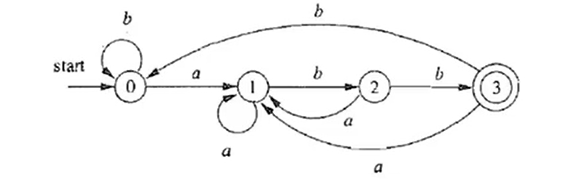
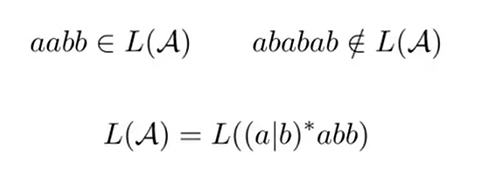
约定:所有没有对应出边的字符默认指向一个“死状态”(不可能再被接收)
其确定性在于:
- 只对字符表中的字符做状态转移
- 每个状态下对每个字符都有唯一的状态转移

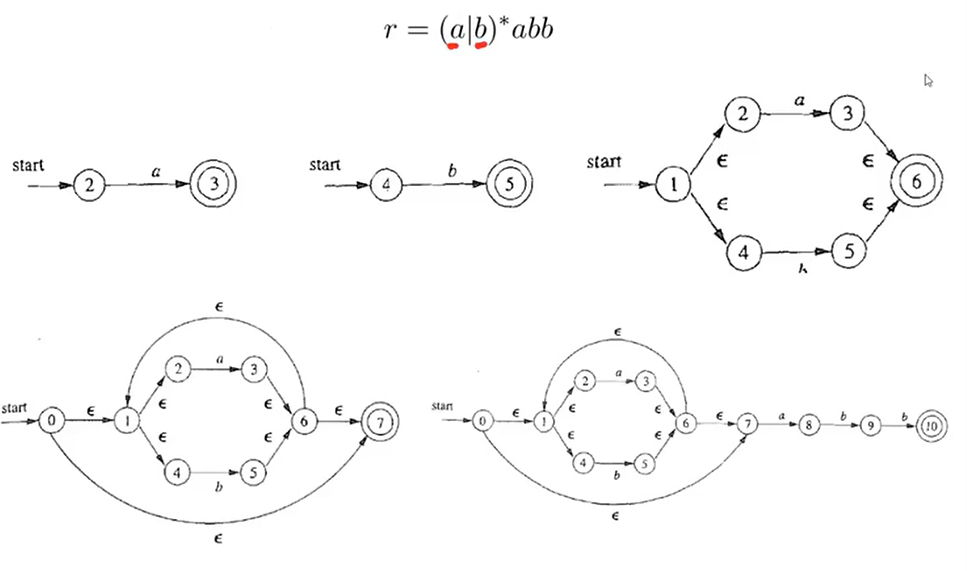
Thompson 构造法(RE to NFA)

依据正则表达式的定义,分步处理:
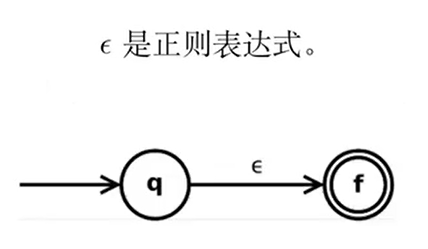
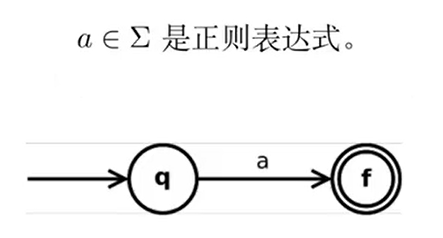
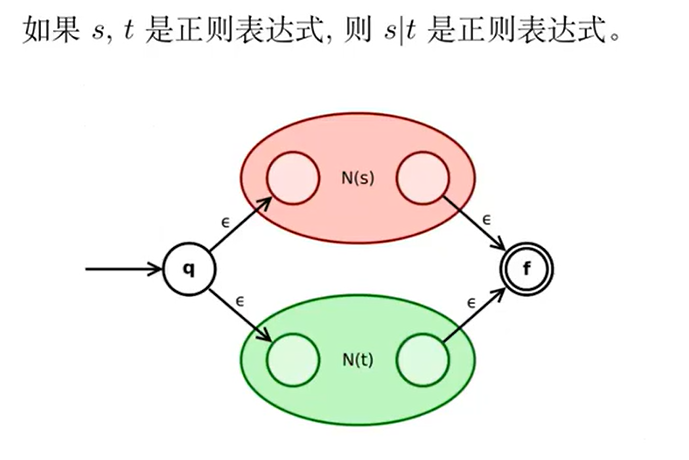
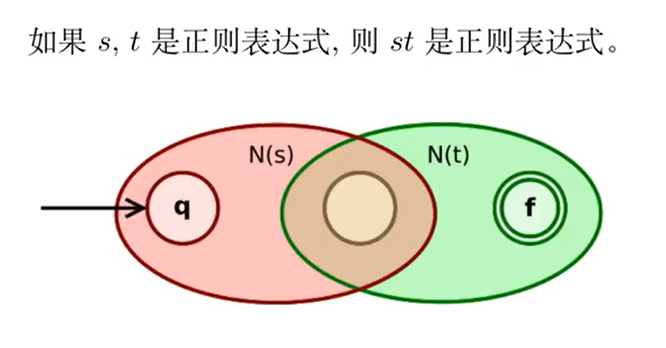
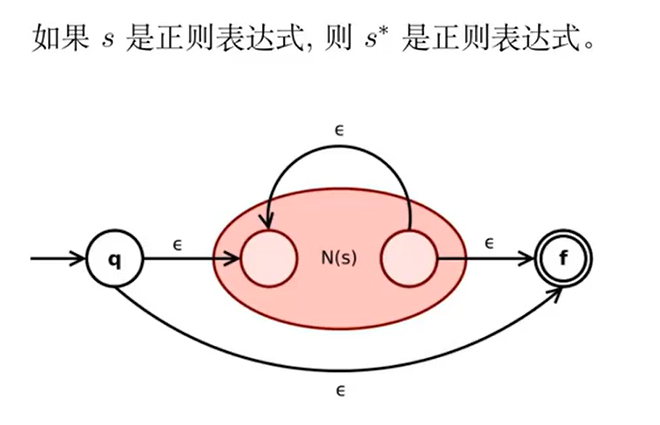
分析:

例子:
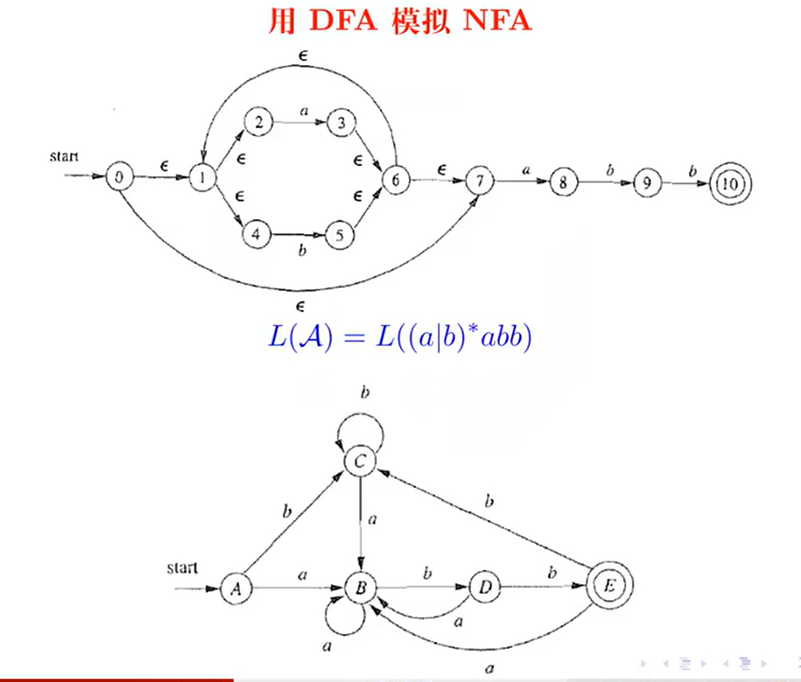
子集构造法(NFA to DFA)
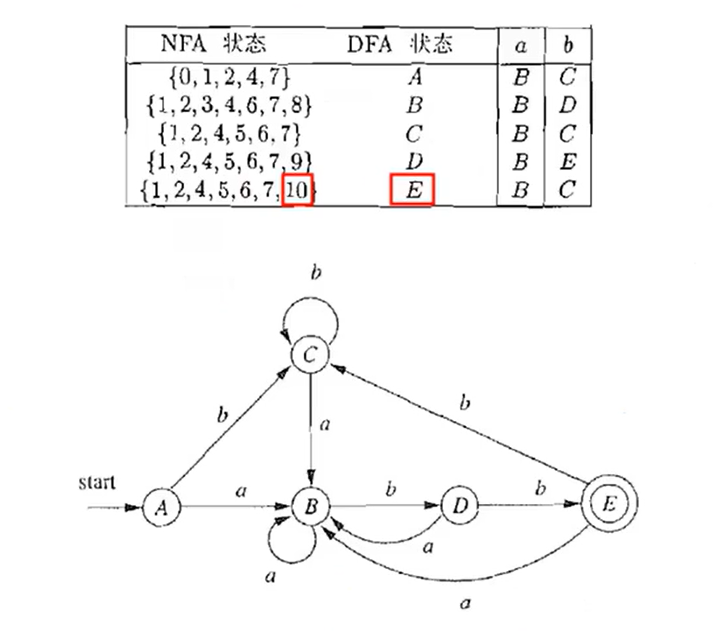


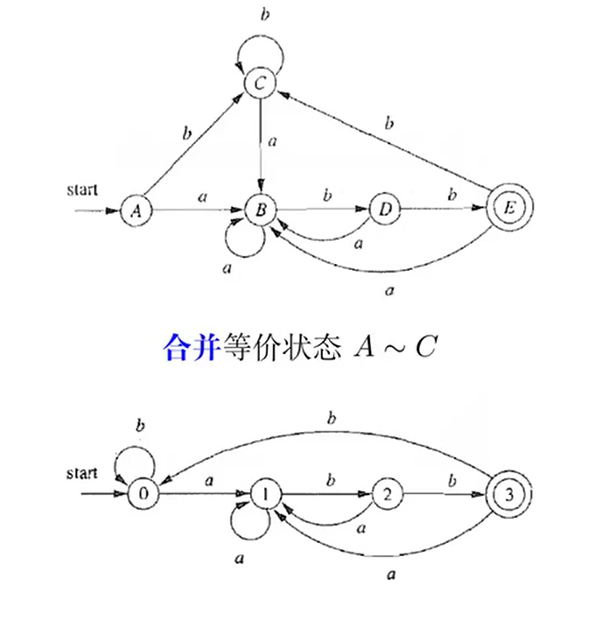
DFA 最小化(DFA to 最简等价DFA)
DFA 最小化的基本思想:等价的状态可以合并

出发点:

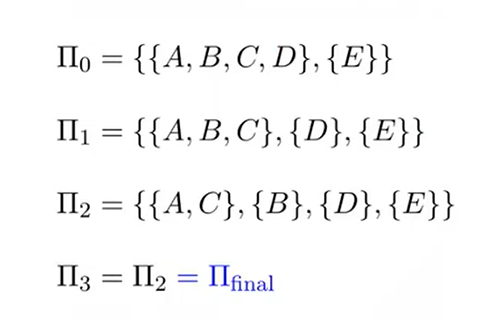
DFA 最小化算法总结:

算法要在严格定义的 DFA 上执行,注意要先检查是否需要补全“死状态”
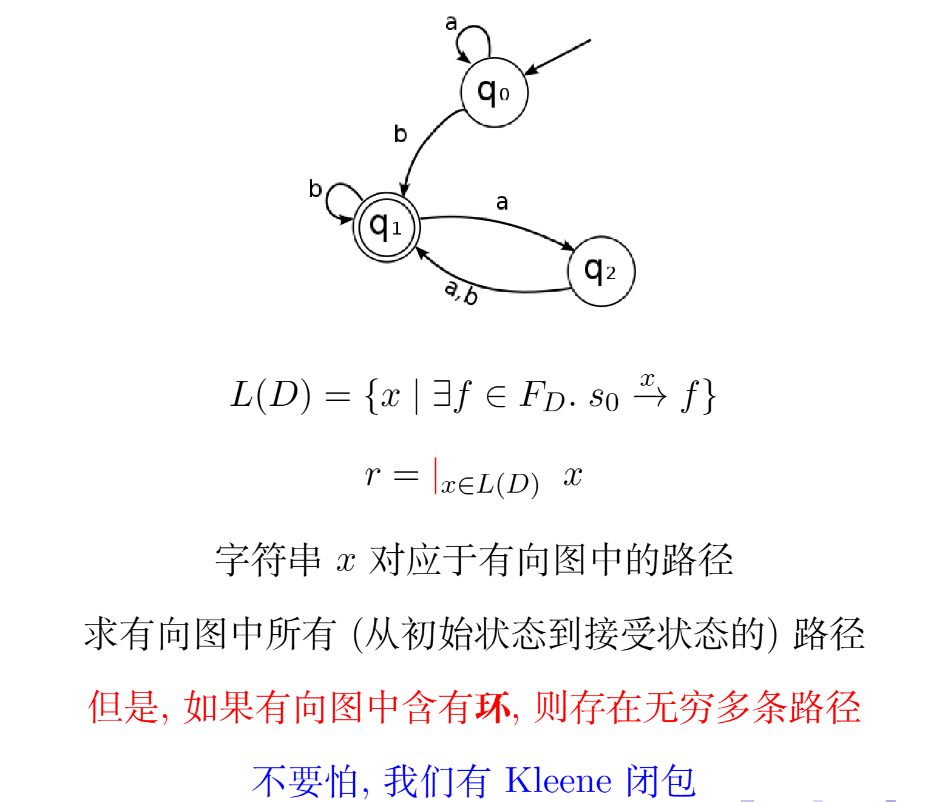
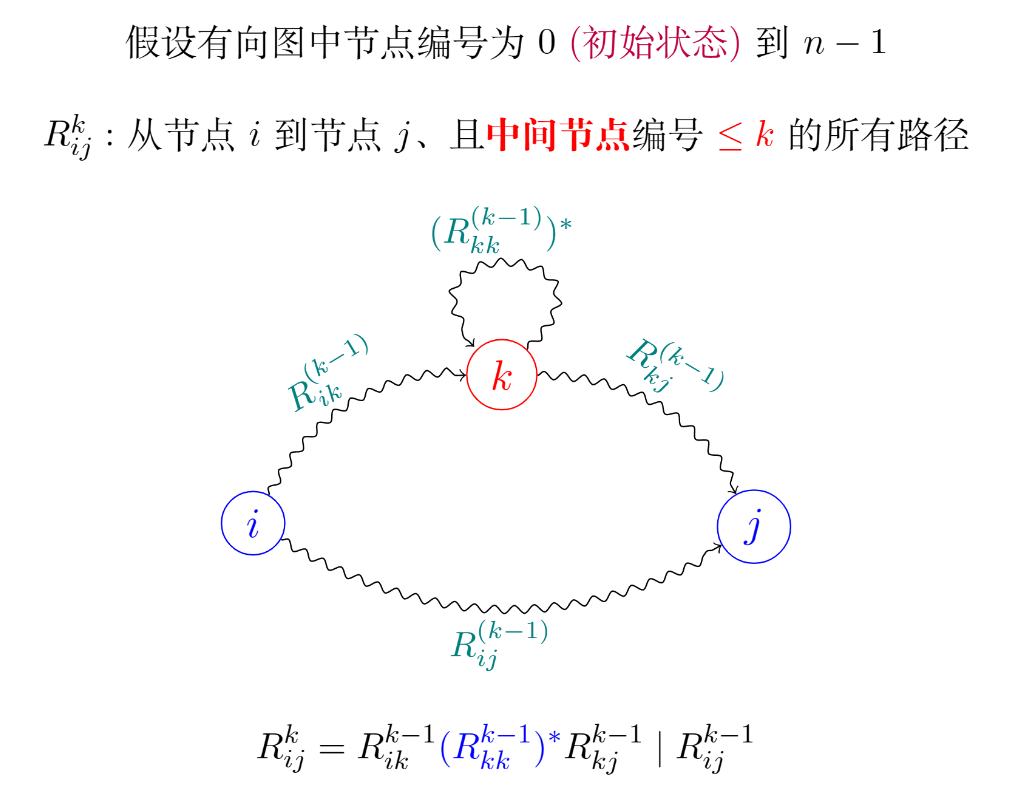
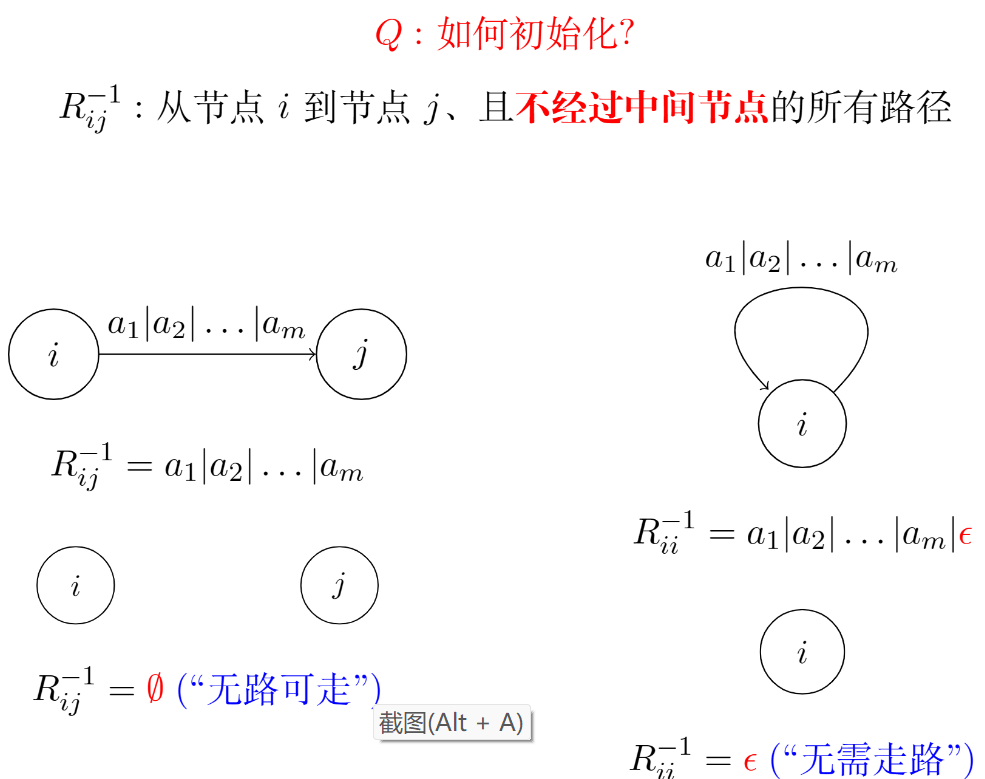
Kleene 构造法(DFA to RE)


词法分析器生成
遵循规则:最前优先匹配,最长优先匹配
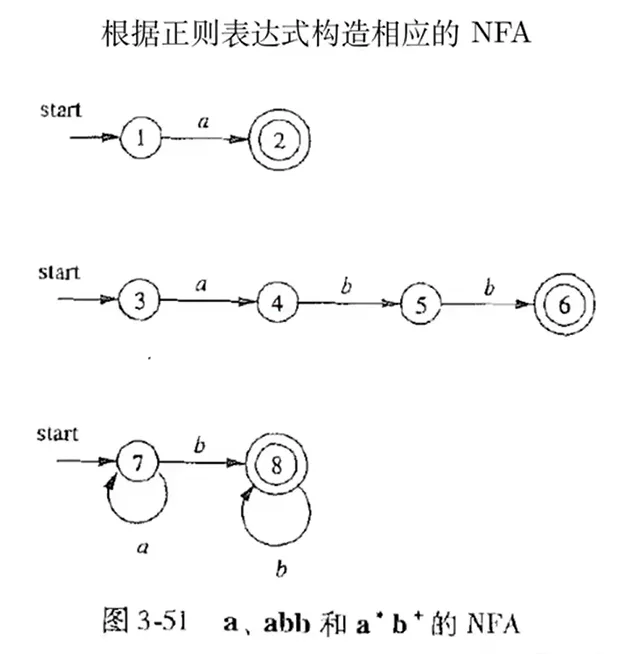
根据正则表达式构造相应的 NFA
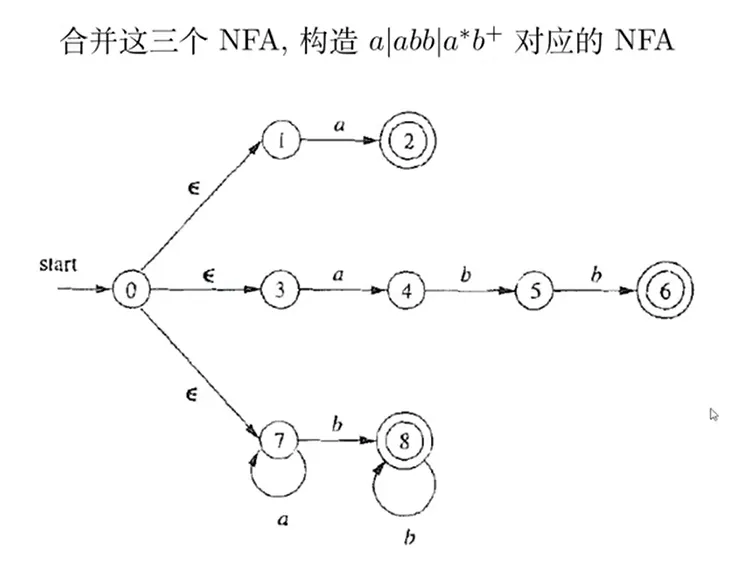
合并 NFA,构造完整词法规则的 NFA
使用子集构造法将 NFA 转化为等价 DFA(并消除“死状态”)
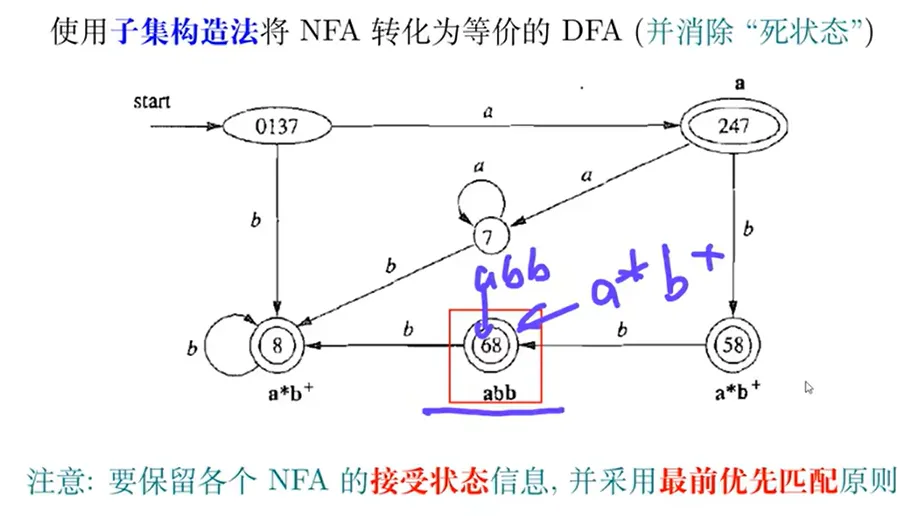
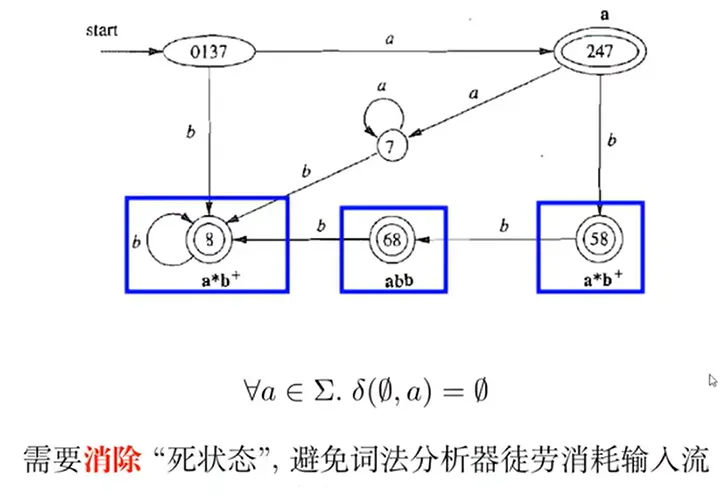
特定于词法分析器的 DFA 最小化(可选)
初始划分不能把所有终止状态笼统地分成一类,需要考虑不同的词法单元,按照识别不同词法单元规约分成不同的类,并补全“死状态”(然后再正常根据 DFA 最小化算法进行处理)

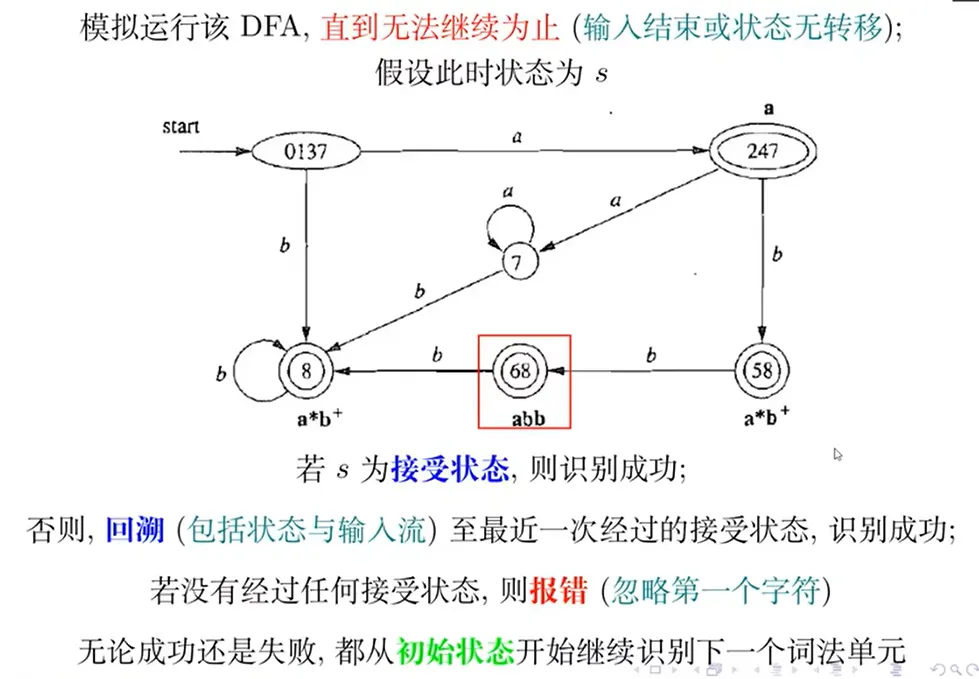
模拟运行该 DFA,直到无法继续运行为止(输入结束或状态无法转移)
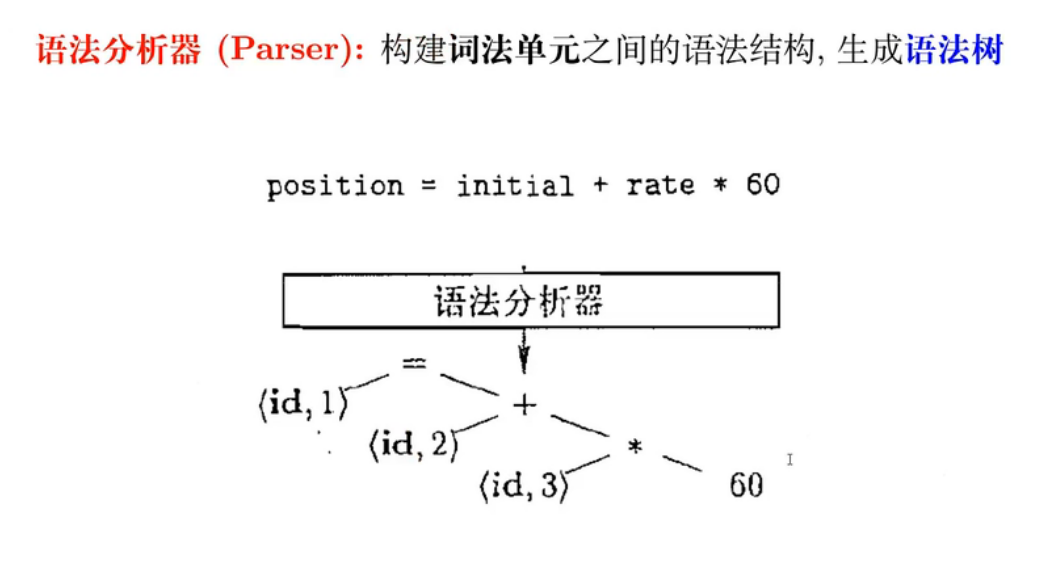
04 - 语法分析器
ANTLR v4 生成语法分析器
(已通过SysYLexer.g4生成对应的词法分析器)
- 输入:语法归约
SysYParser.g4 - 输出:语法分析器及访问生成的语法树的辅助类
SysYParser.tokens,SysYParser.interp,SysYParser.java,SysYParserBaseListener.java,SysYParserBaseVisitor.java,SysYParserListener.java,SysYParserVisitor.java- ANTLR 提供了 Visitor 和 Listener 两种访问语法树节点的方式,即访问者模式和观察者模式
样例:(来自 lab2)
1 | parser grammar SysYParser; |
二义性文法
例如:stmt:”if” expr “then” stmt “else” stmt ; 是一个二义性文法(if-else 的匹配问题)
可以通过改写来消除二义性(将 else 与最近的未匹配的 if 相匹配):
1 | stmt : matched_stmt | open_stmt ; |
例如:expr:expr “*” expr | expr “+” expr | DIGIT ; 是一个二义性文法(运算符的结合性和优先级)
常识告诉我们乘法的优先级比加法高,并且两者都是左结合的
1 | /* 左递归文法 */ |
ANTLR 可以通过算法直接处理二义性文法和具有左公因子的文法,无需人为改写(优先级高的写在前)
ANTLR 中二元运算符默认为左结合,一元运算符默认为右结合,对于右结合的二元运算符,使用关键字 assoc 加以限定,expr:<assoc = right> expr “^” expr
上下文无关文法


一些复杂的例子
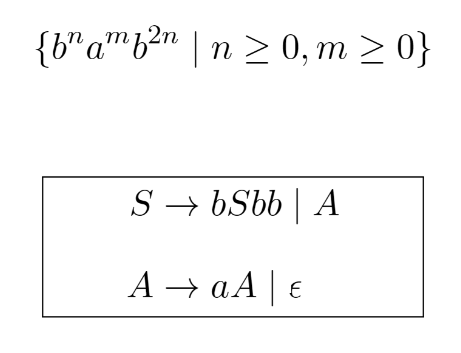
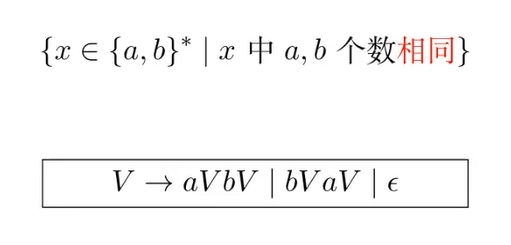

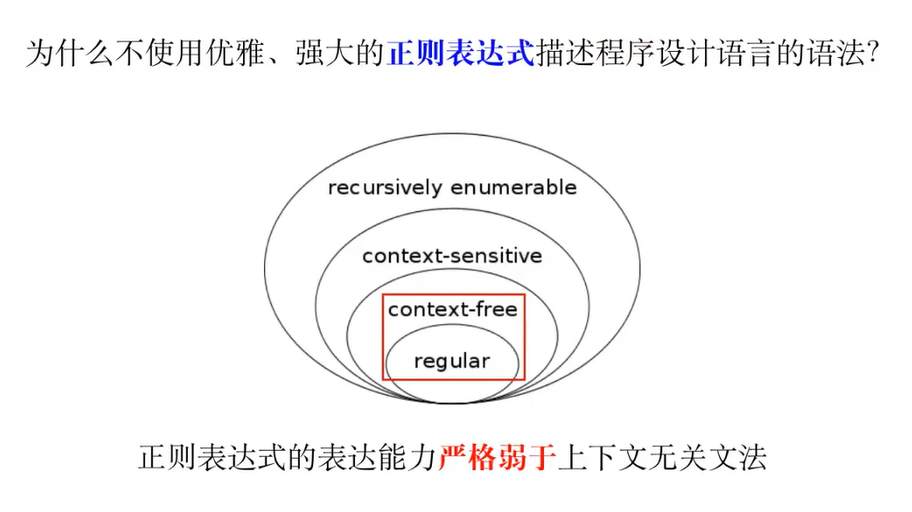
上下文无关文法的表达能力强于正则表达式


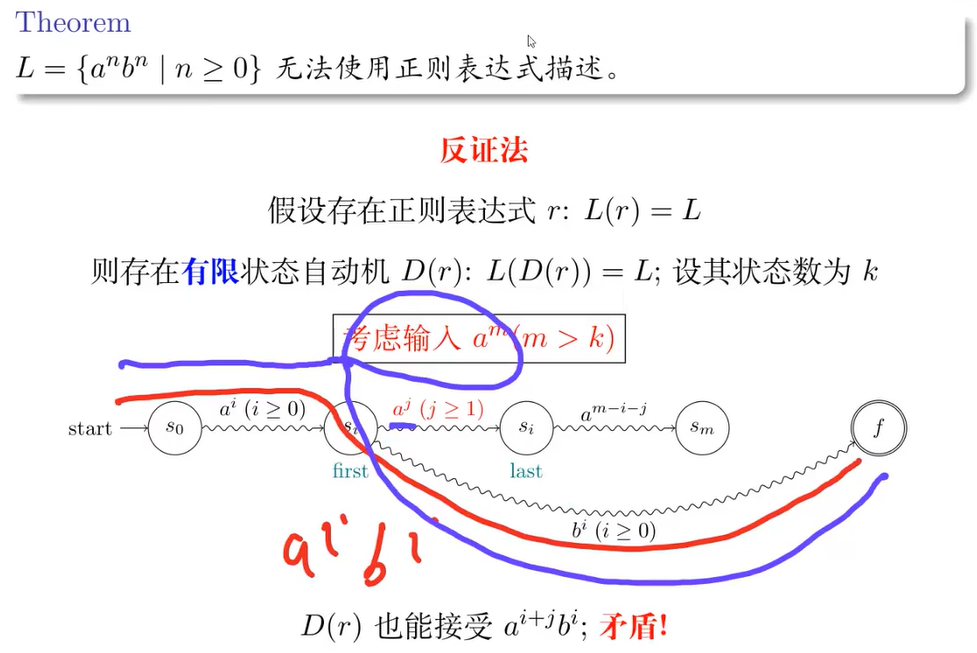
证明一个上下文无关文法没有二义性
对于 A → X | Y | Z,要证明:
- L(X) ∩ L(Y) = Ø
- L(Y) ∩ L(Z) = Ø
- L(Z) ∩ L(X) = Ø
其中,L(X) 表示 X 所定义的语言
故,更一般的,对于 A → X1 | X2 | X3 | … | Xn,需要证明,∀ i, j ∈ [1, n] (i != j),有 L(Xi) ∩ L(Xj) = Ø
05 - 语法分析算法
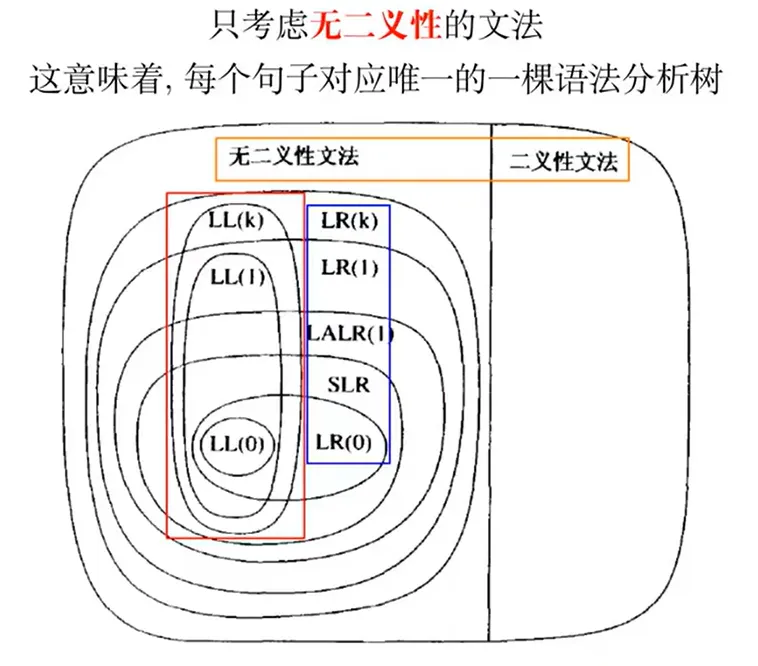
LL(1) 语法分析算法
自顶向下的,递归下降的,基于分析预测表的,适用于 LL(1) 文法的 LL(1) 语法分析器
自顶向下
LL(1) 从左往右读入词法单元(left-to-right),并且在推导的每一步,总是选择最左边的非终结符进行展开(left-most description)
递归下降

分析预测表
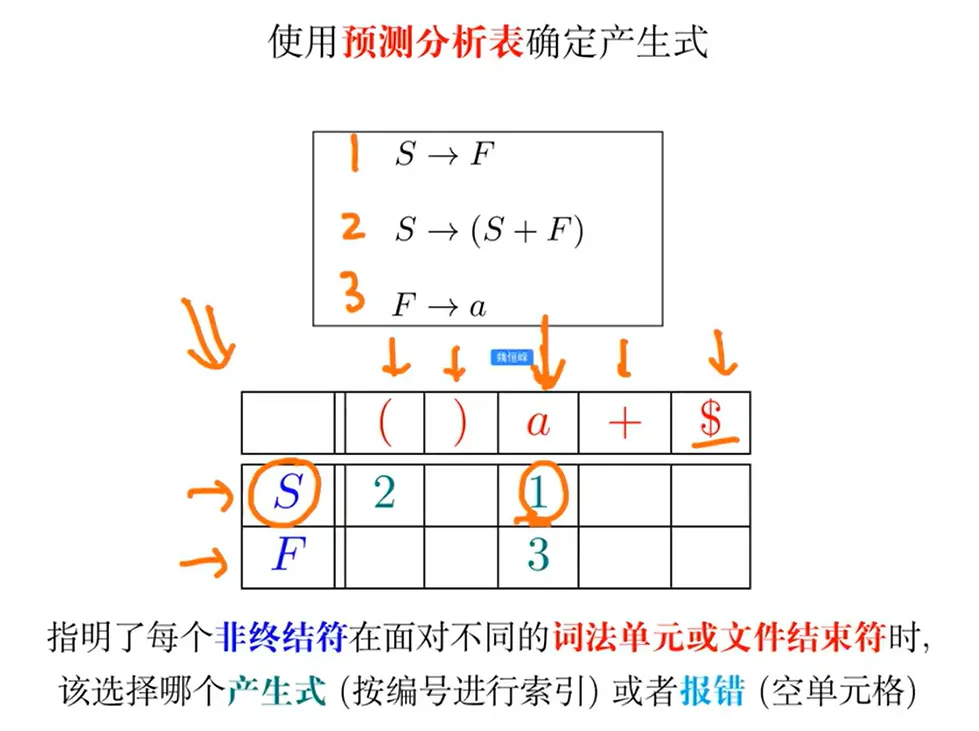
LL(1) 文法

实现样例
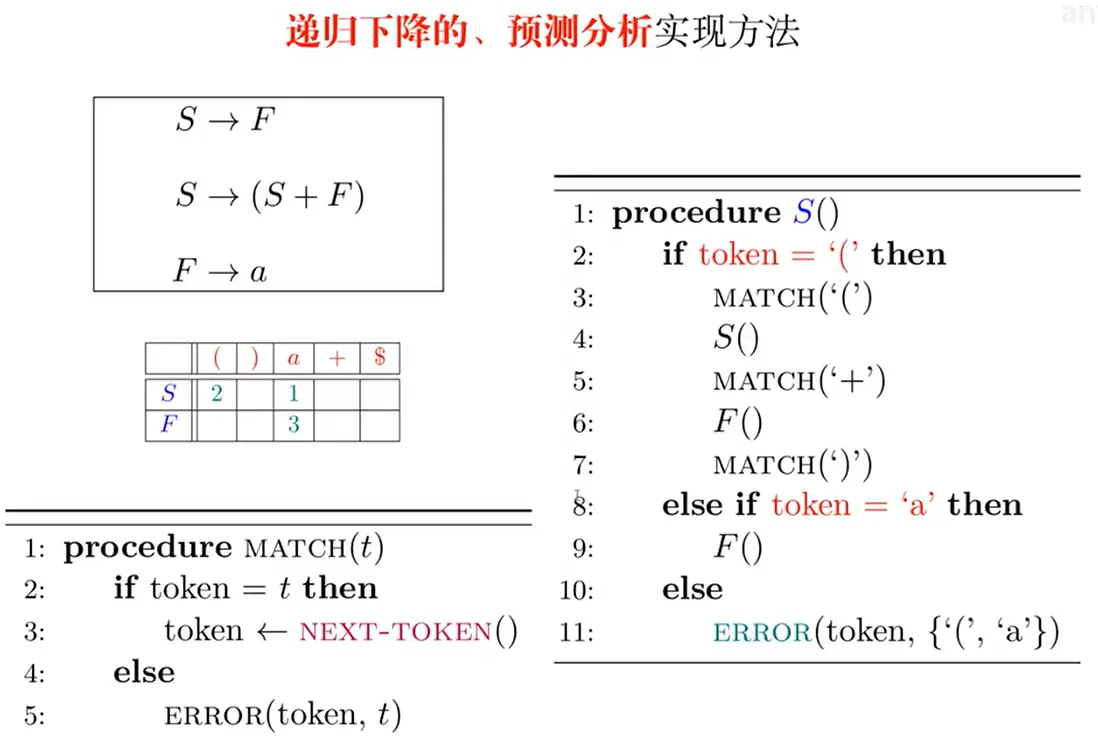
计算给定文法 G 的预测分析表
First 集合


Follow 集合


计算 First 集合
对于每个符号串 α 的产生式:α = X1 X2 X3 … Xm
- 先计算每个 X 的 First(X) 集合

- 再计算每个符号串 α 的 First(α) 集合

计算 Follow 集合
- 为每个非终结符 X 计算 Follow(X) 集合

生成预测分析表

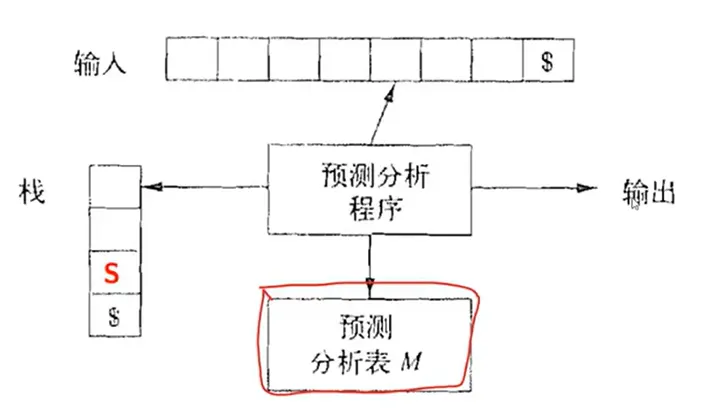
非递归的预测分析算法

改造非 LL(1) 文法
- 消除左递归(使用右递归)
- 提取左公因子
Adaptive LL(*) 语法分析算法(AllStar 算法)
关于 ANTLR v4:

处理左递归+优先级

优先级上升算法
变为非左递归,然后用迭代的方式进行处理
展开递归表达式时,需要一个优先级参数
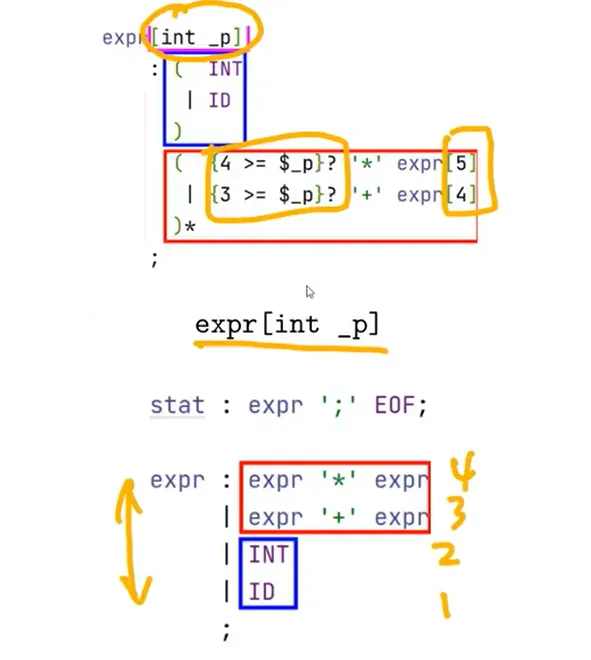
更多例子:








进行错误报告与恢复
恐慌/应急模式(Panic Mode):假装成功,调整状态,继续进行



AllStar 算法

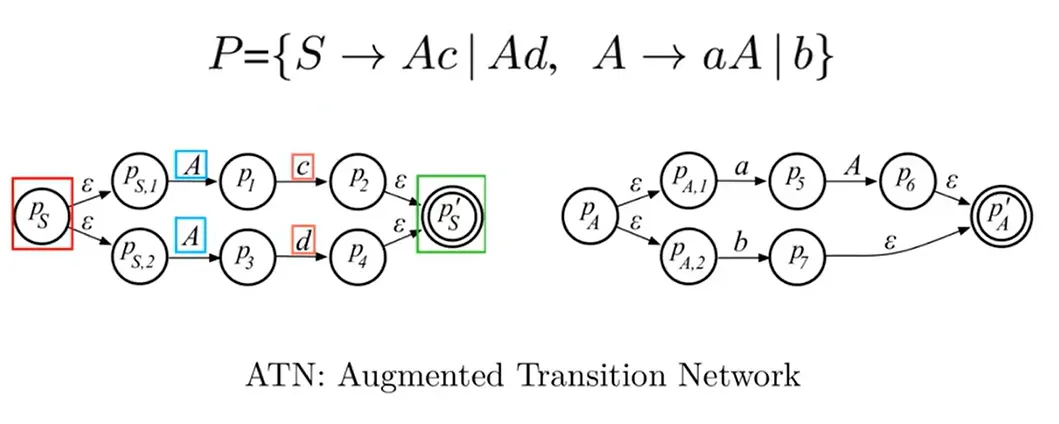
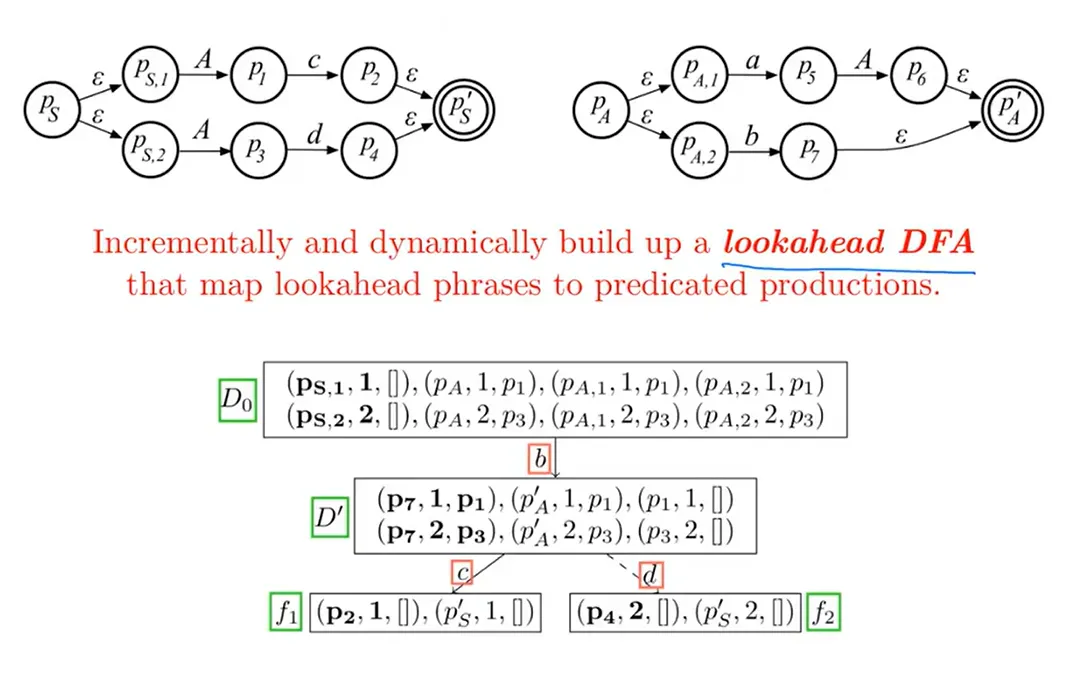
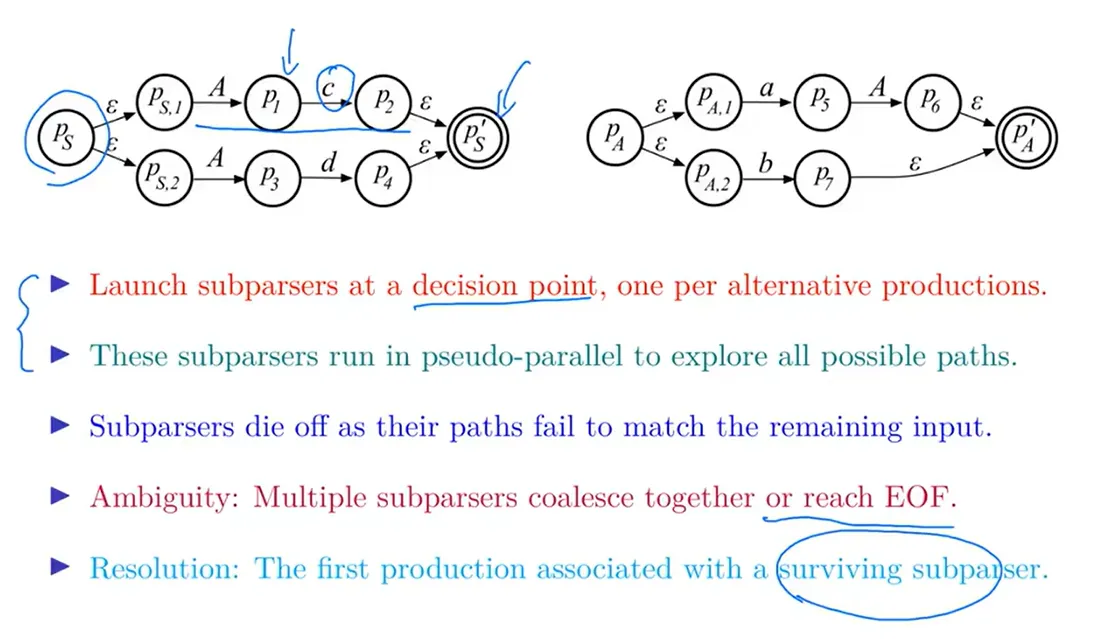
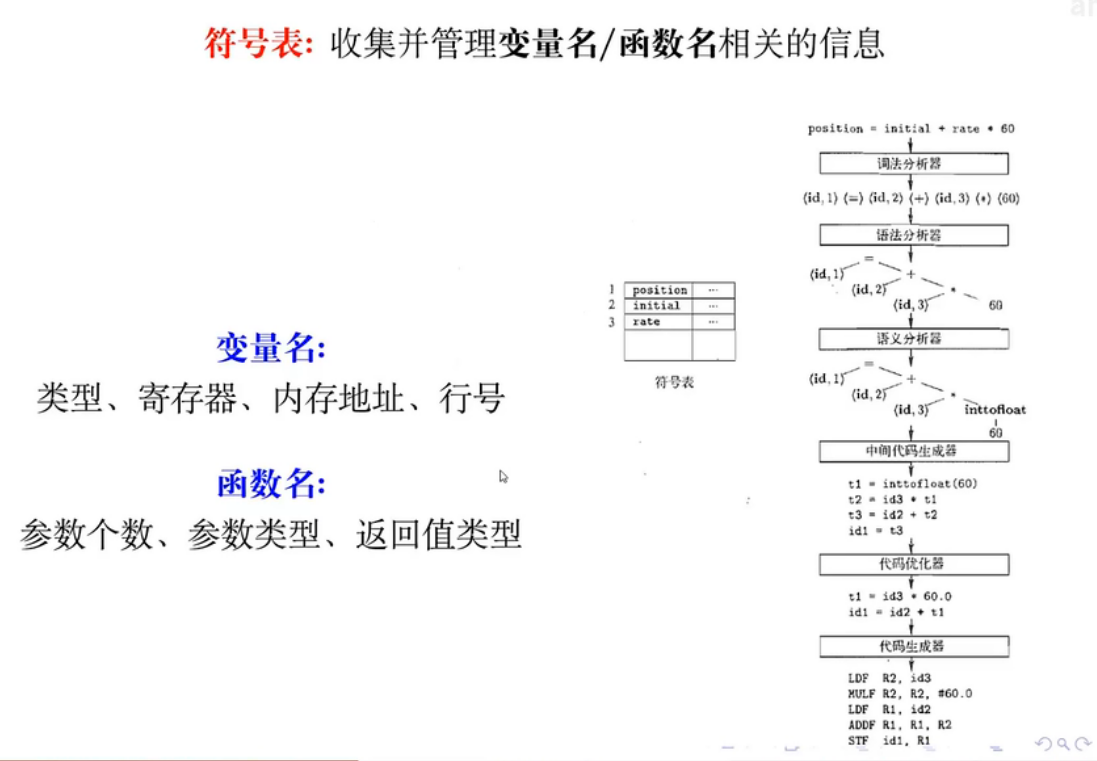
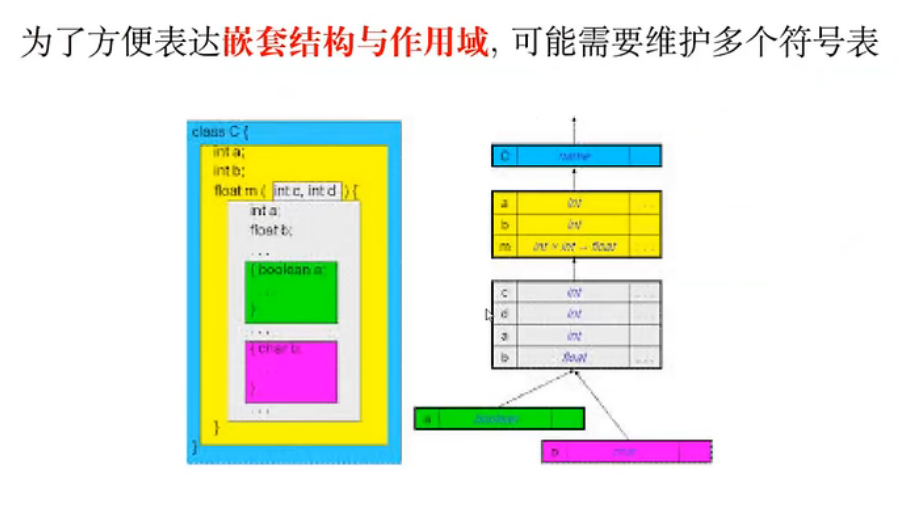
06 - 符号表
每个符号表代表了一个作用域,不同的作用域需要通过树结构来维护:
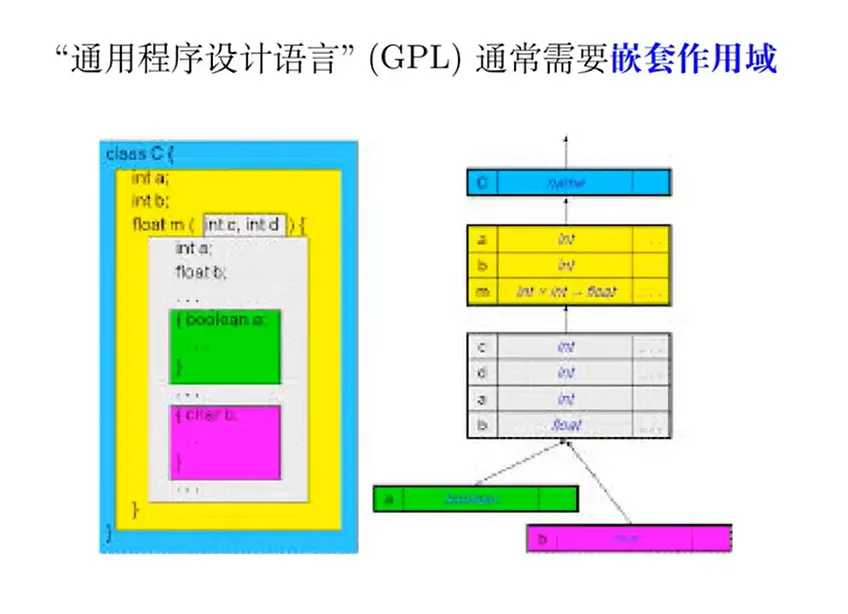
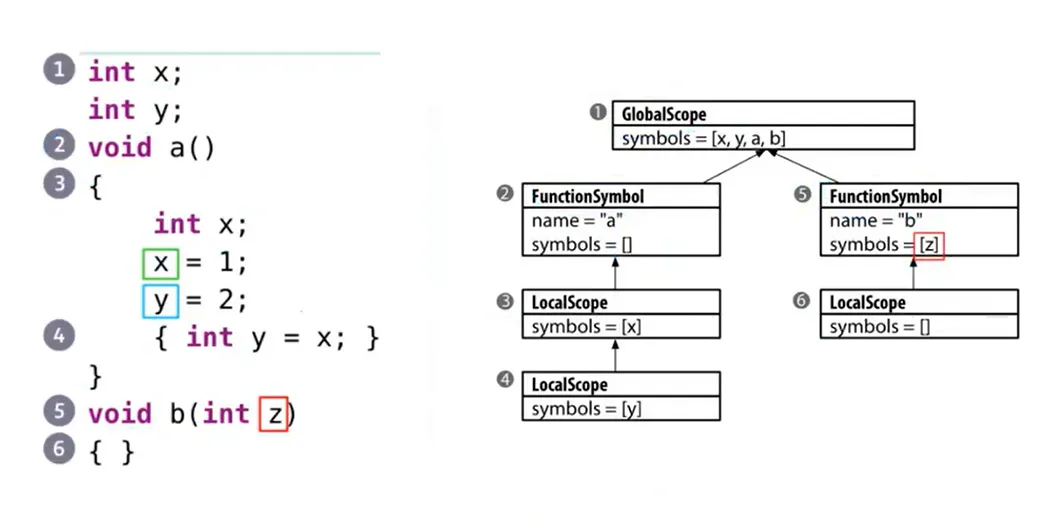
每个作用域需要提供的接口:

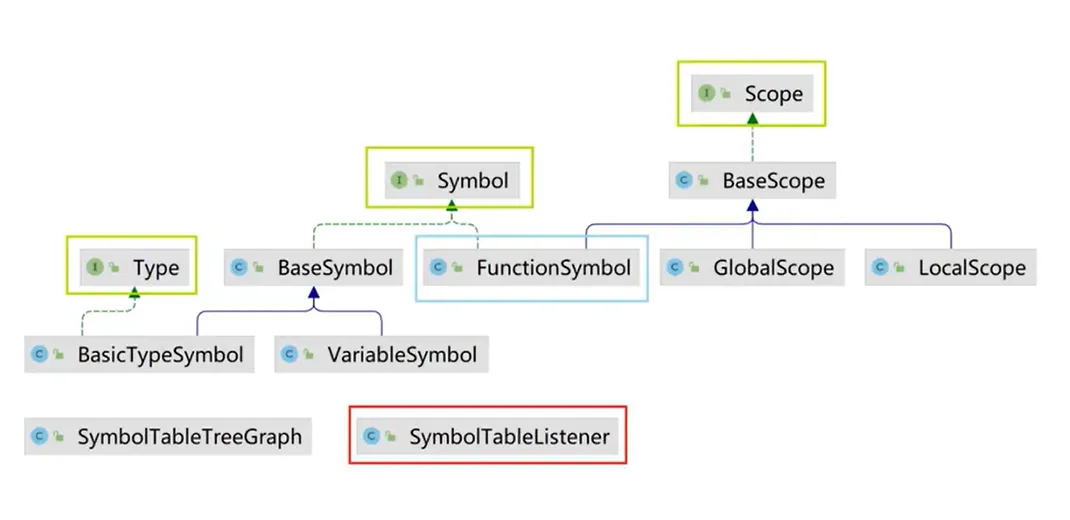
符号表相关的类层次结构设计
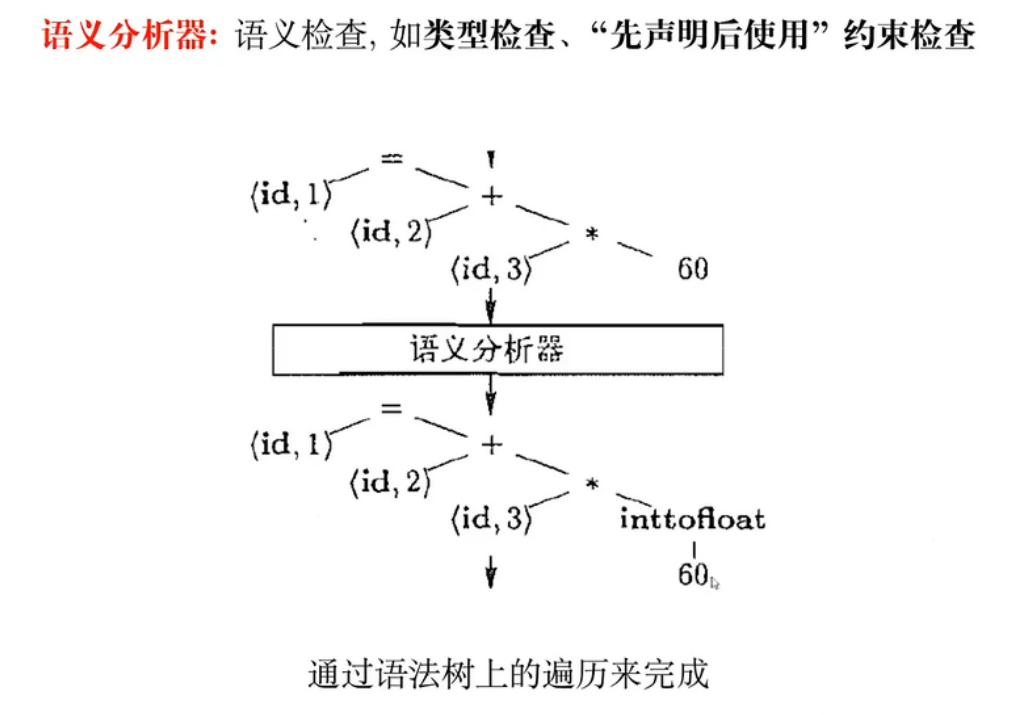
07 - 语义分析
类型系统与类型检查
类型检查
类型转换
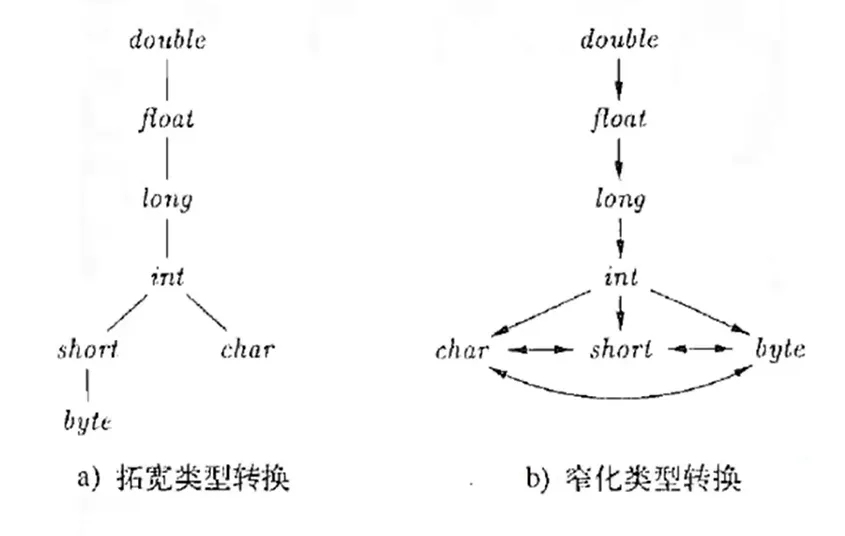
- 类型综合

- 类型推导

生成数组类型的类型表达式
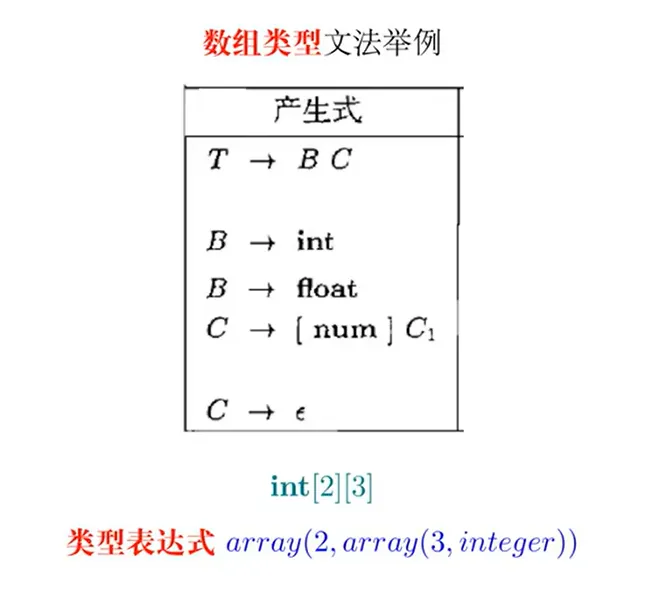
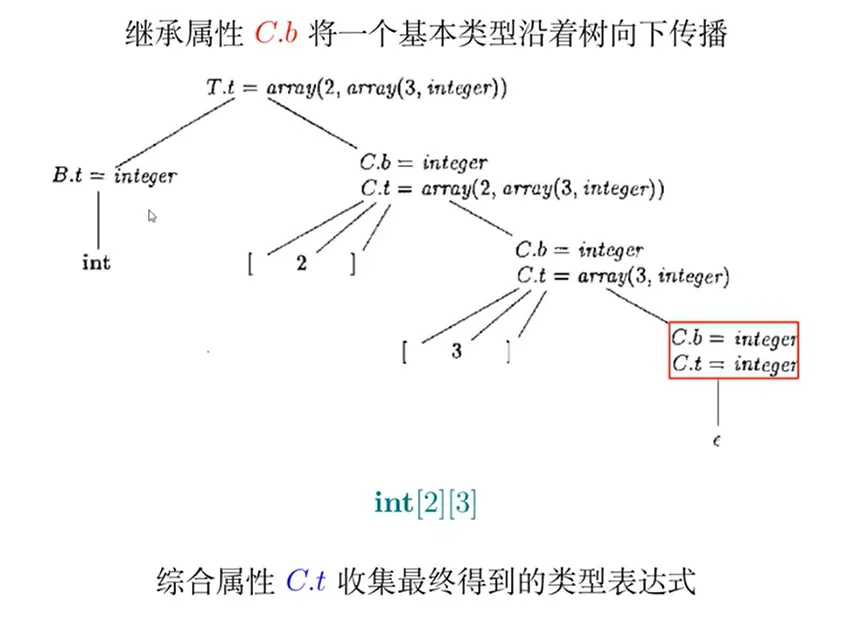
属性文法
属性文法:为上下文无关文法赋予语义
关键问题:如何基于上下文无关文法做上下文相关分析?(语法分析树上的有序信息流动,DFS 遍历)

在 ANTLR v4 中,使用参数的形式来表示继承属性,使用返回值来表示综合属性
(代码演示部分略)
语法制导定义

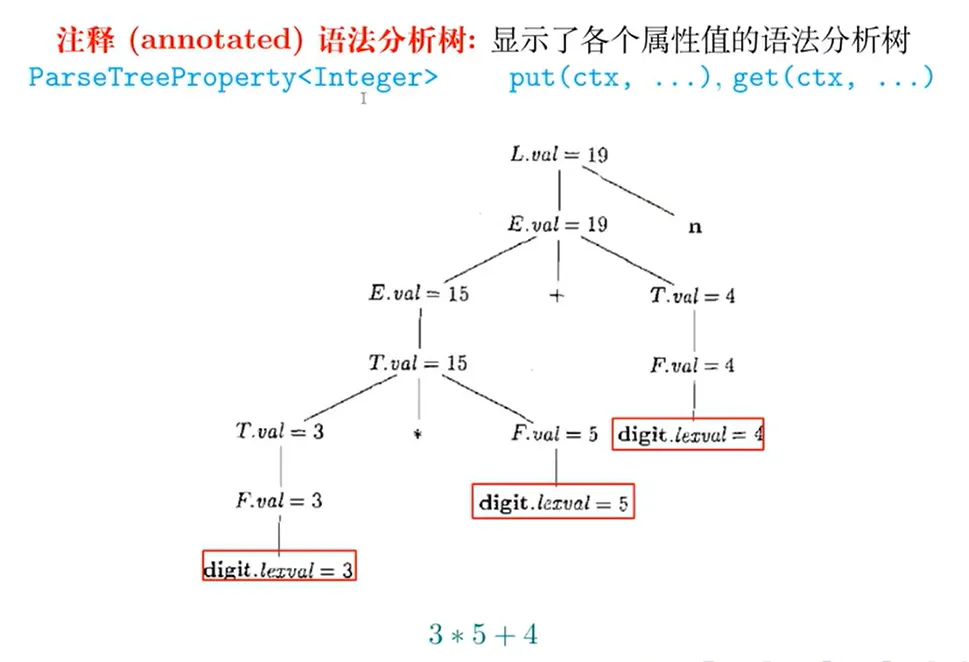
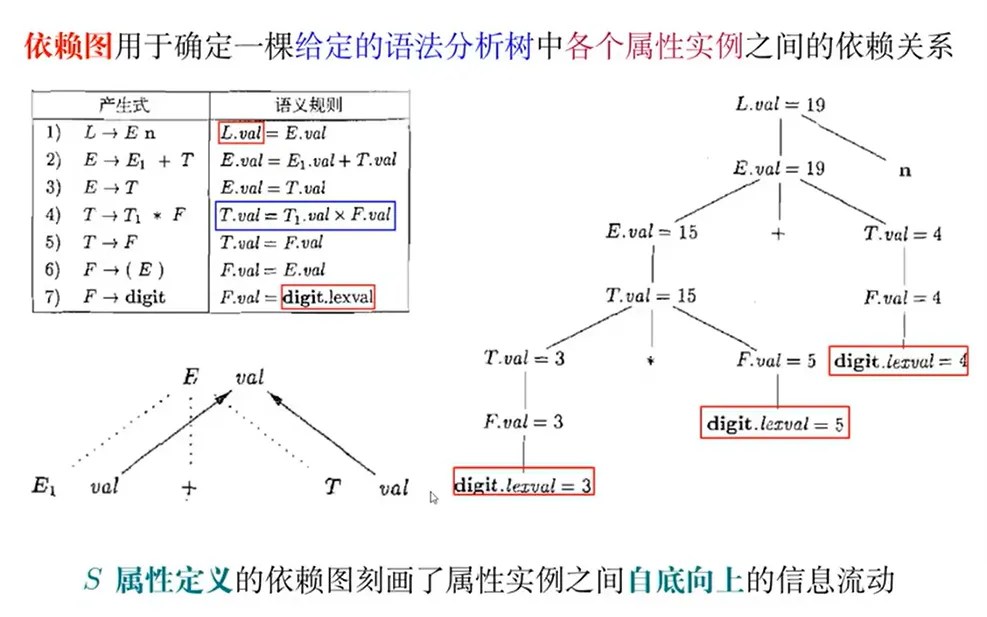
S 属性定义
综合属性



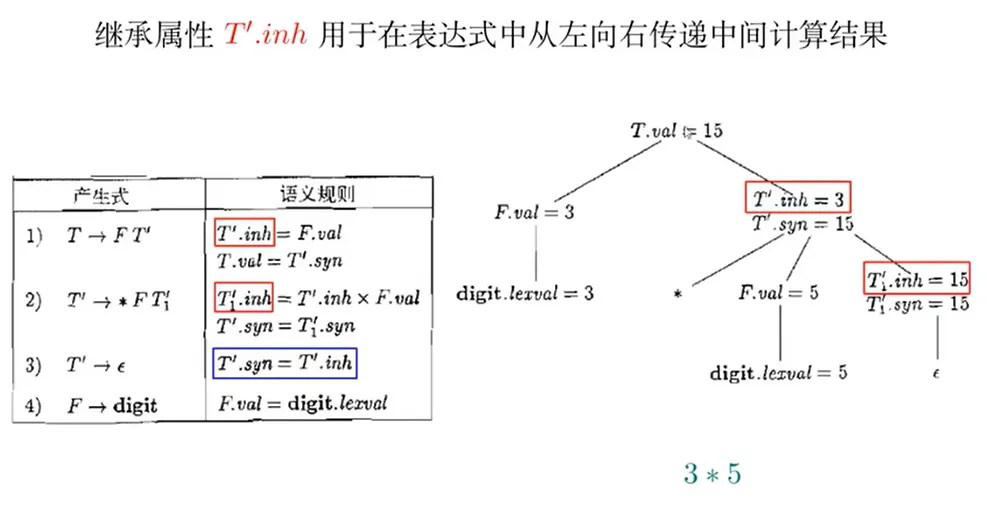
L 属性定义
继承属性


- 例子:属性文法计算后缀表达式


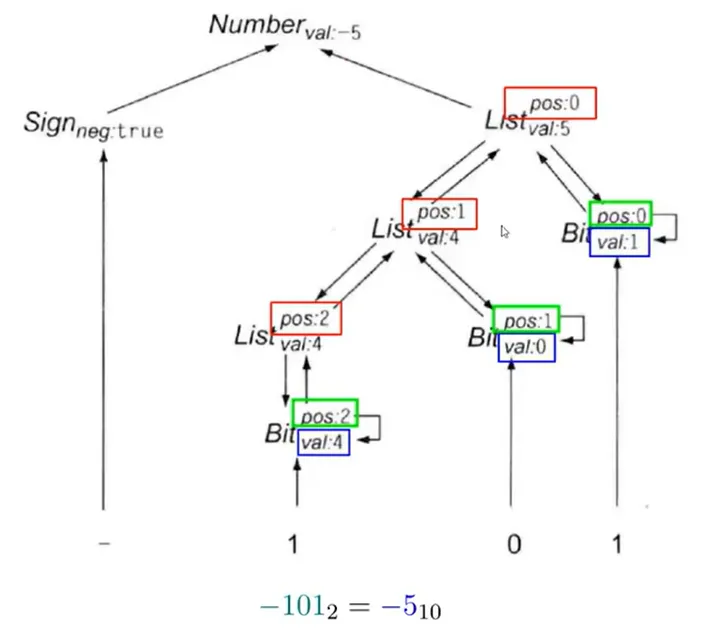
- 例子:属性文法计算有符号二进制数


语法制导的翻译方案

将带有语义规则的 SDD 转换为带有语义动作的 SDT:
- S 属性的翻译方案

- L 属性定义与 LL 语法分析
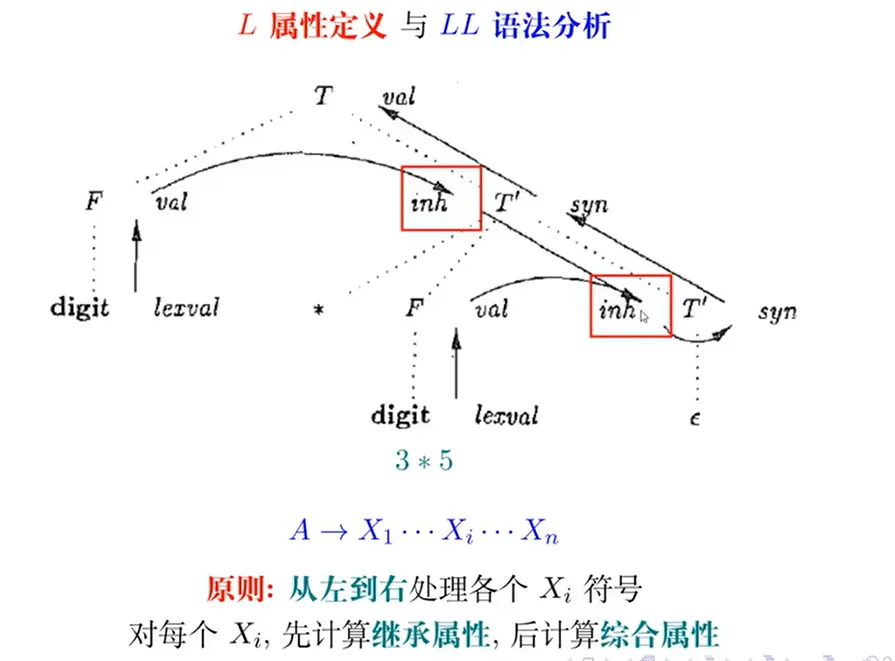

- 比较:在左递归与右递归上的属性定义

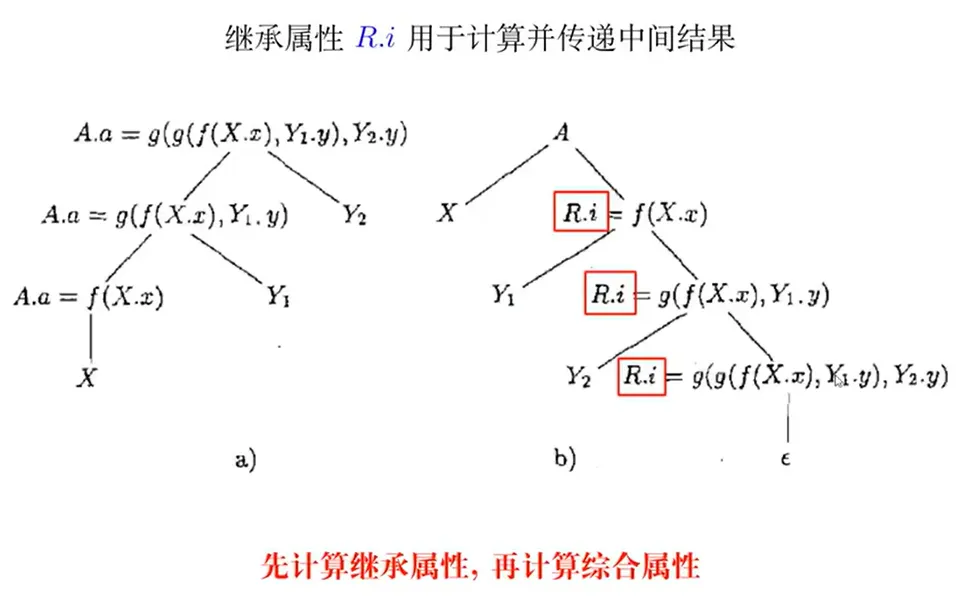
- L 属性翻译方案


- L 属性翻译方案样例


08 - LLVM IR
LLVM(Low-Level Virtual Machine)
The LLVM Compiler Infrastructure
The LLVM Project is a collection of modular and reusable compiler and tool-chain technologies. Despite its name, LLVM has little to do with traditional virtual machines. The name “LLVM” itself is not an acronym; it is the full name of the project.
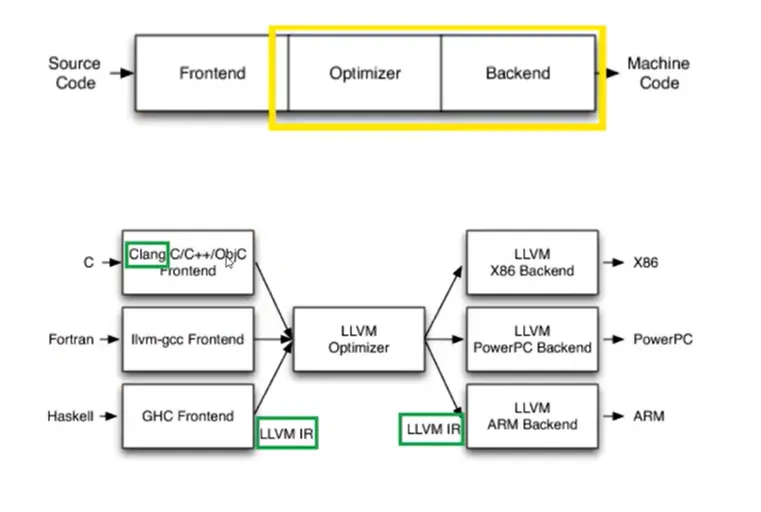
LLVM IR
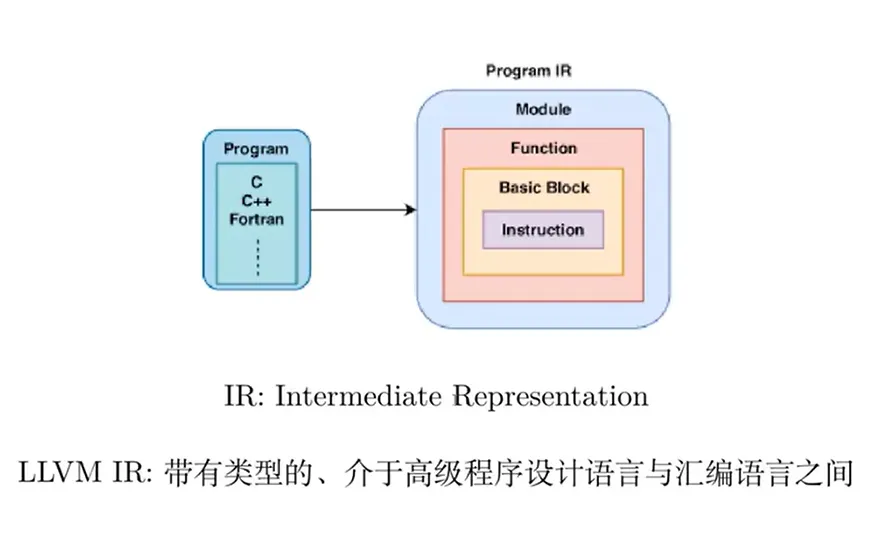
自动生成 LLVM IR
使用命令 clang -S -emit-llvm xxx.c -o xxx.ll 生成 LLVM IR code 样例:

演示代码 1:https://github.com/courses-at-nju-by-hfwei/compilers-antlr/tree/main/src/main/java/llvm/factorial && https://github.com/courses-at-nju-by-hfwei/learning-llvm/tree/main/10-llvm
更多关于 LLVM 的使用:https://pictures-1312865652.cos.ap-nanjing.myqcloud.com/LLVM.pdf
使控制流满足 SSA:Φ 函数根据控制流决定选择 y1 还是 y2
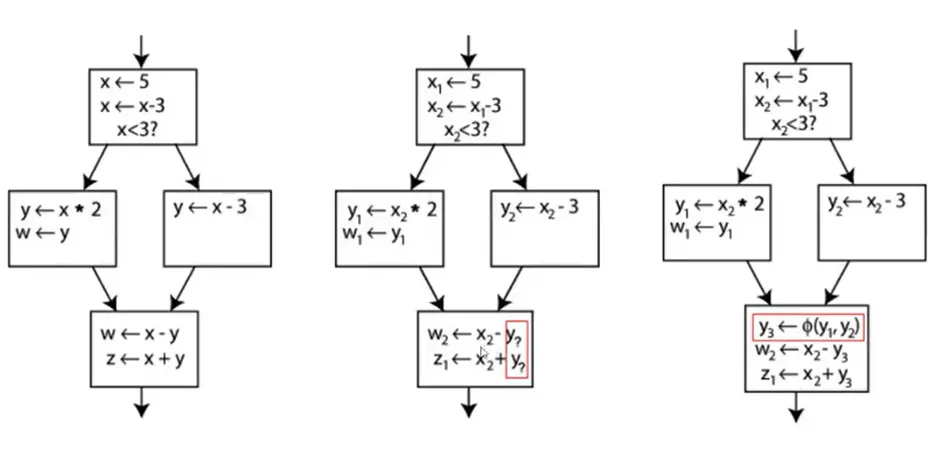
不同优化等级下对控制流的实现方式
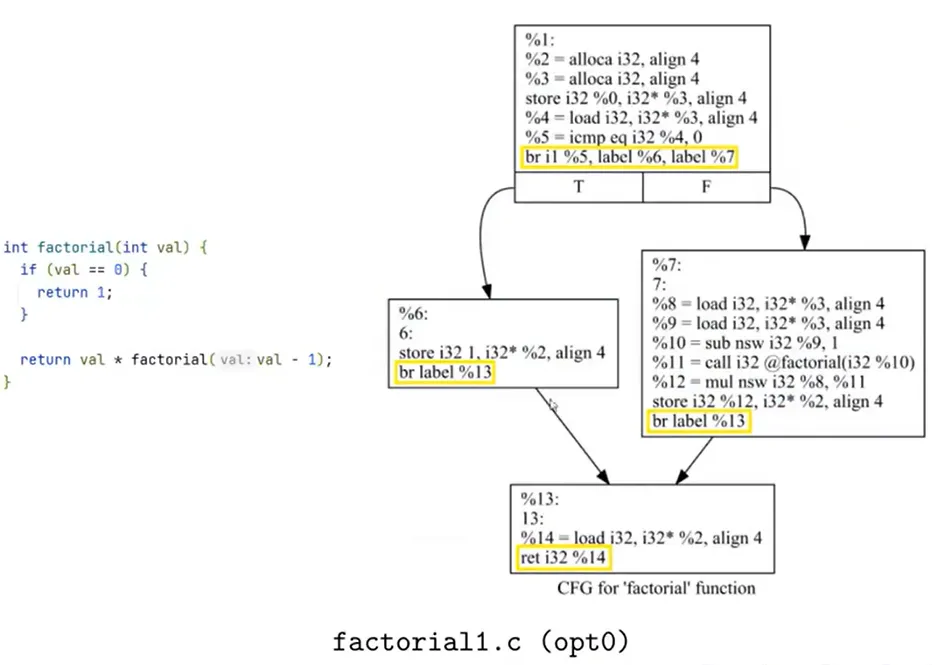
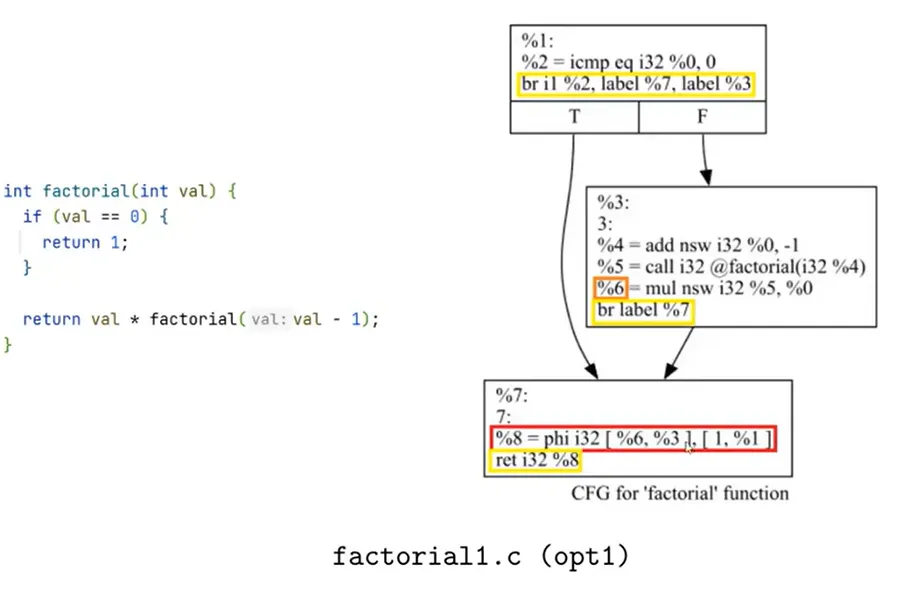
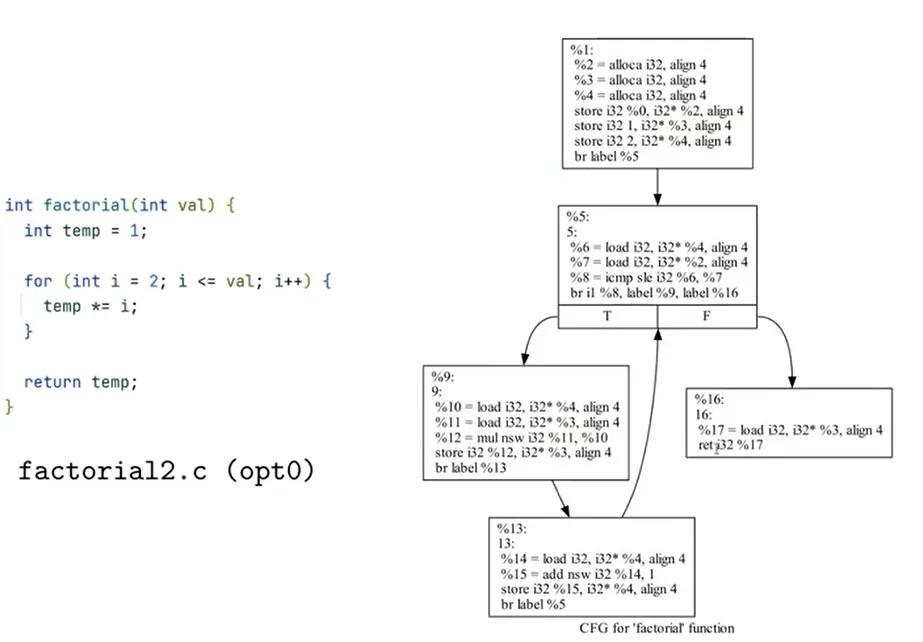
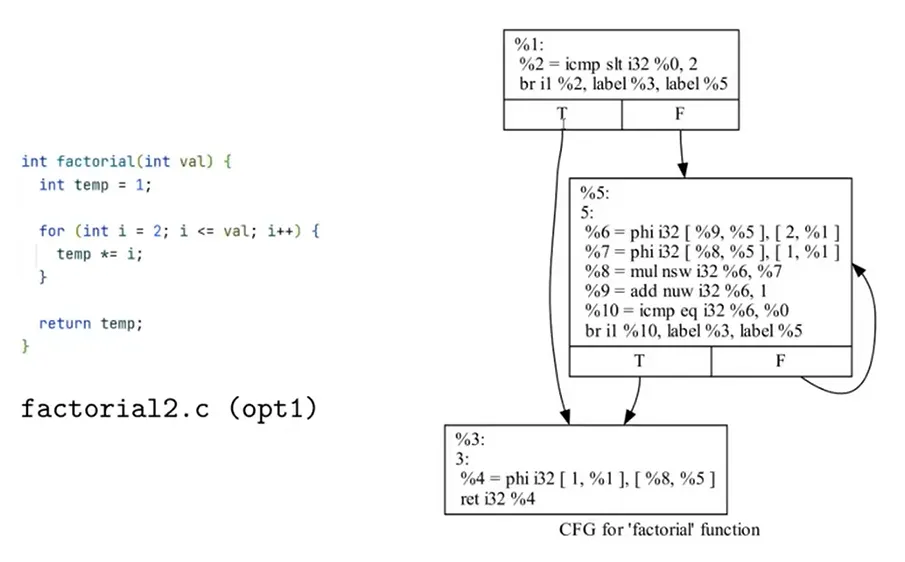
编程方式生成 LLVM IR
详见实验代码
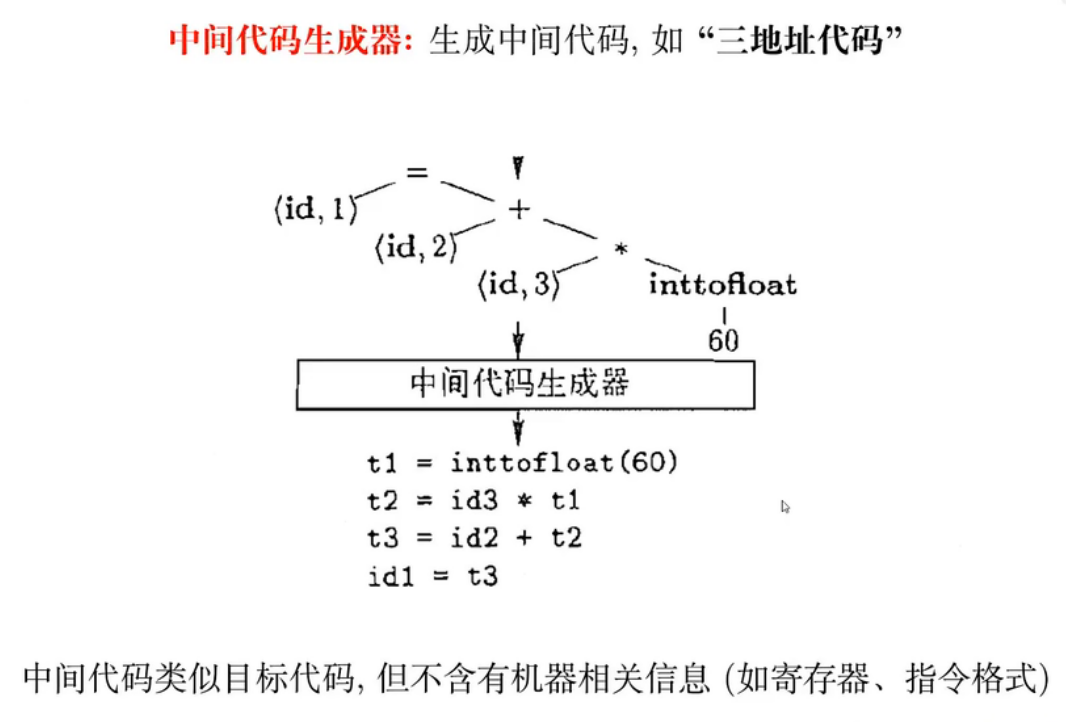
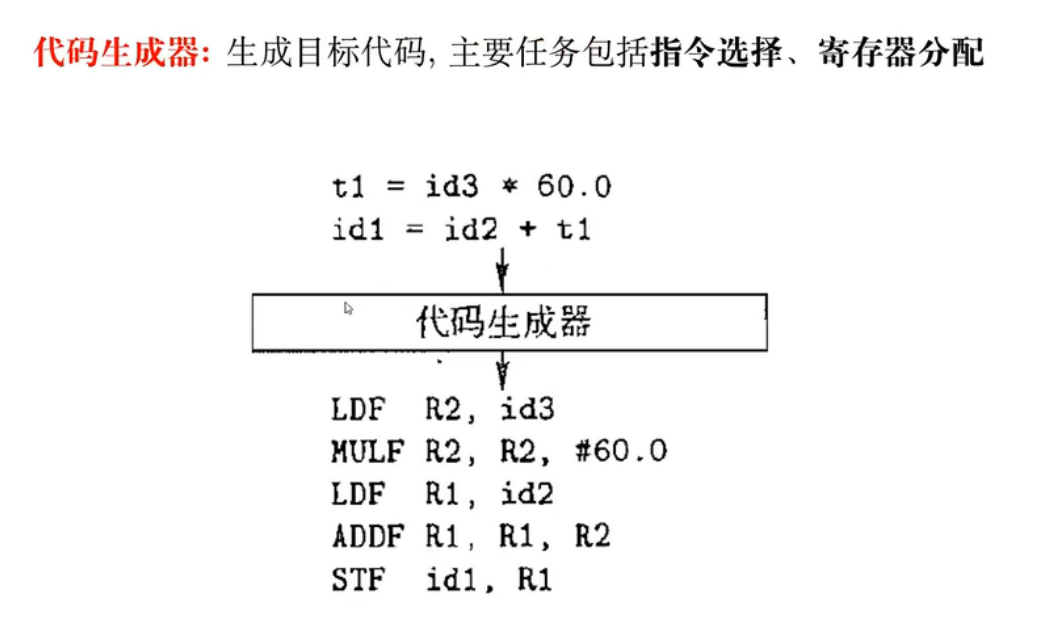
09 - 中间代码生成
表达式翻译与控制流翻译

注意:下图中的文法对布尔表达式和非布尔表达式做出了区分

非布尔表达式的中间代码翻译

数组引用表达式的中间代码翻译
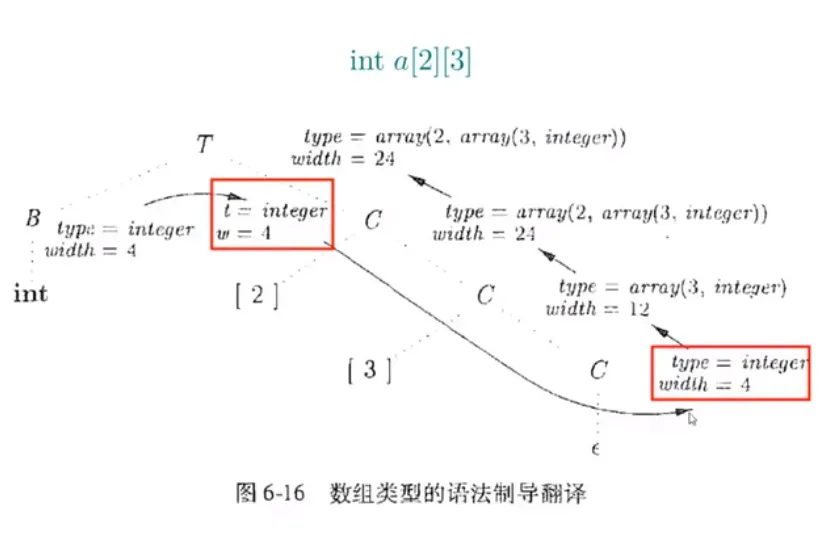

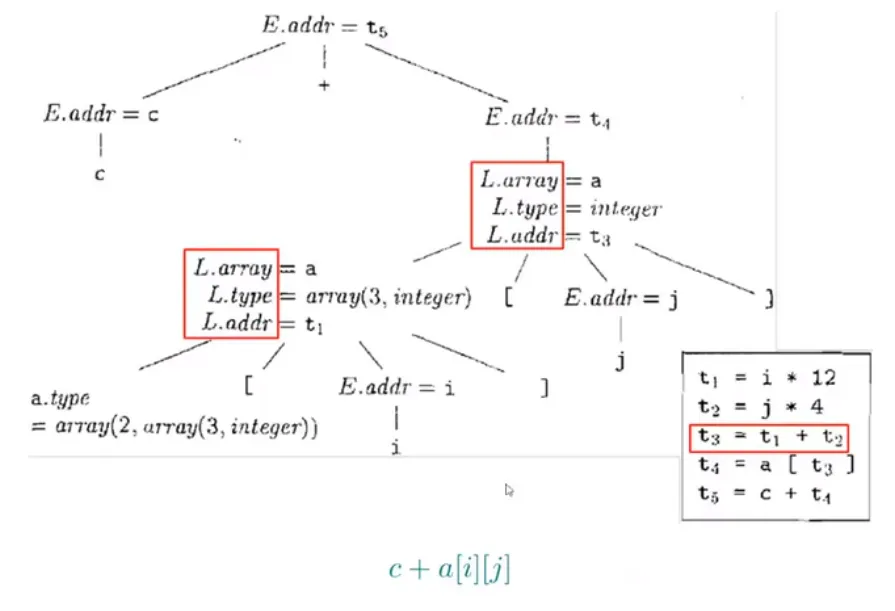
LLVM IR 的生成结果:

控制流语句与布尔表达式的中间代码翻译

if 条件语句:

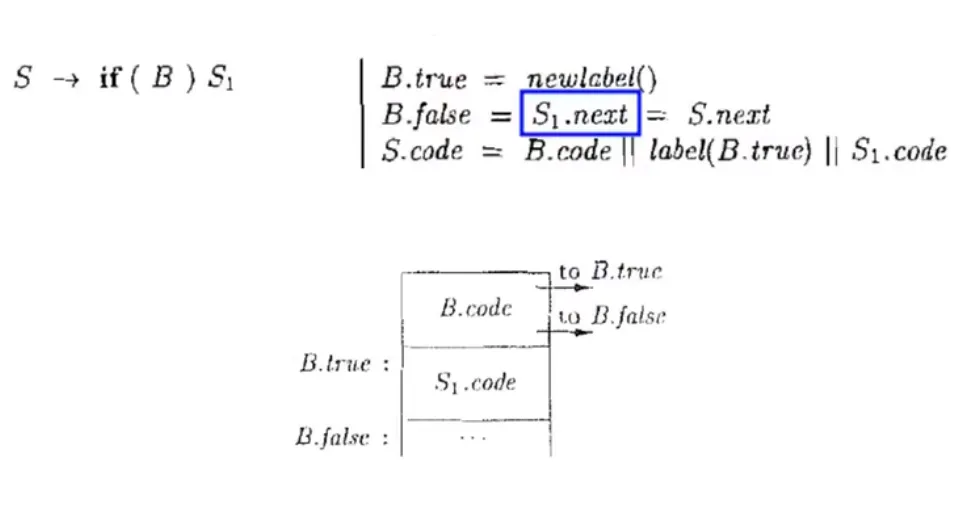
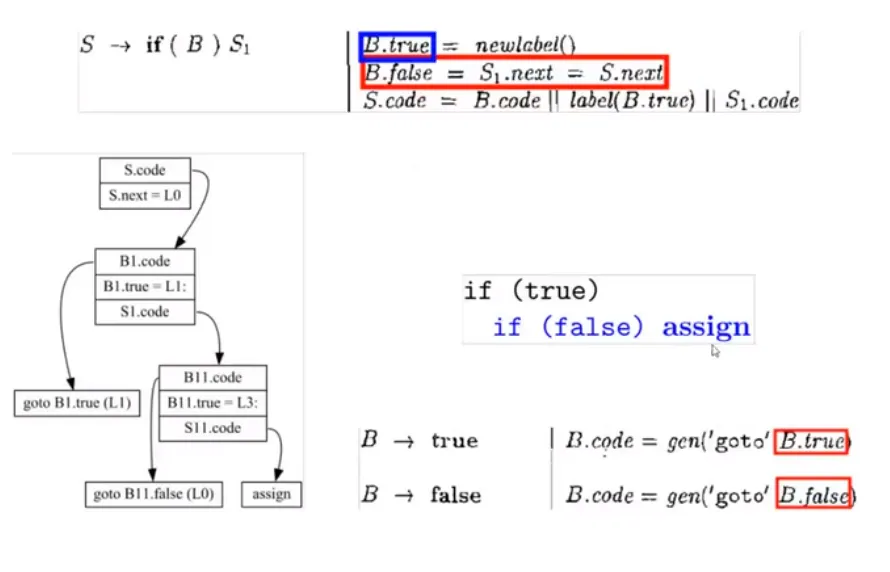
最终生成的 IR code:
1 | goto L1 |
if else 条件语句:
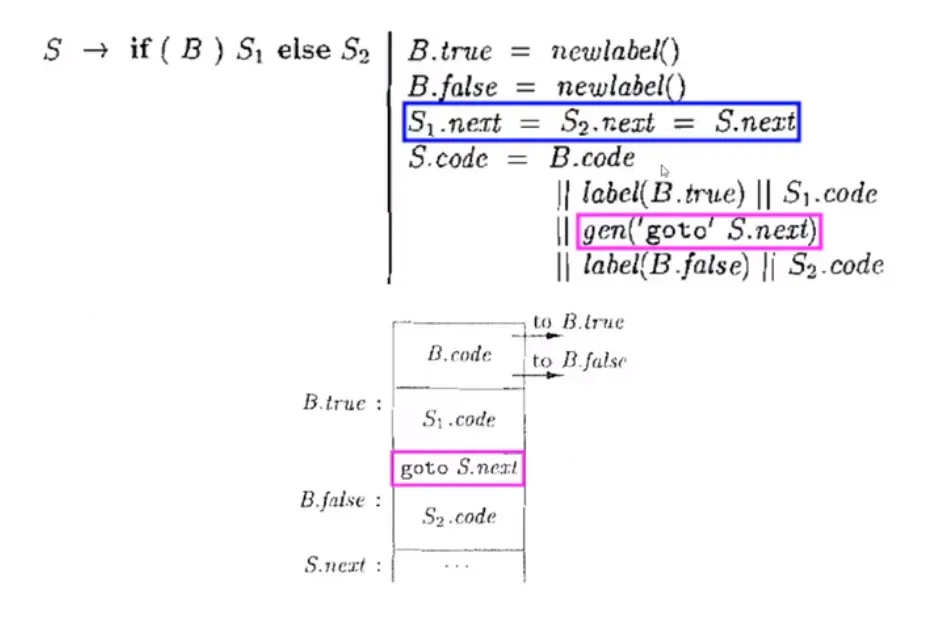
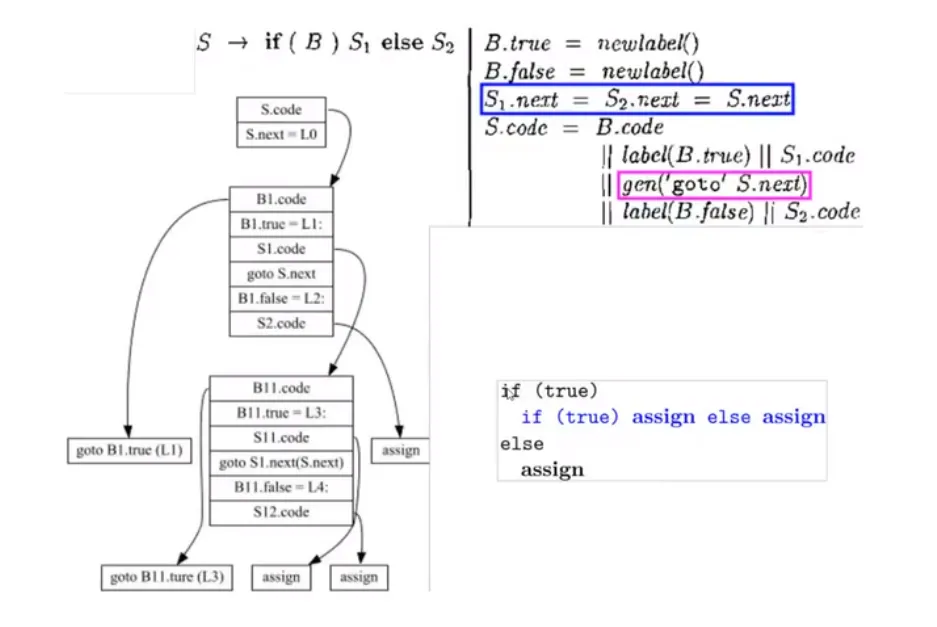
最终生成的 IR code:
1 | goto L1 |
while 循环语句:
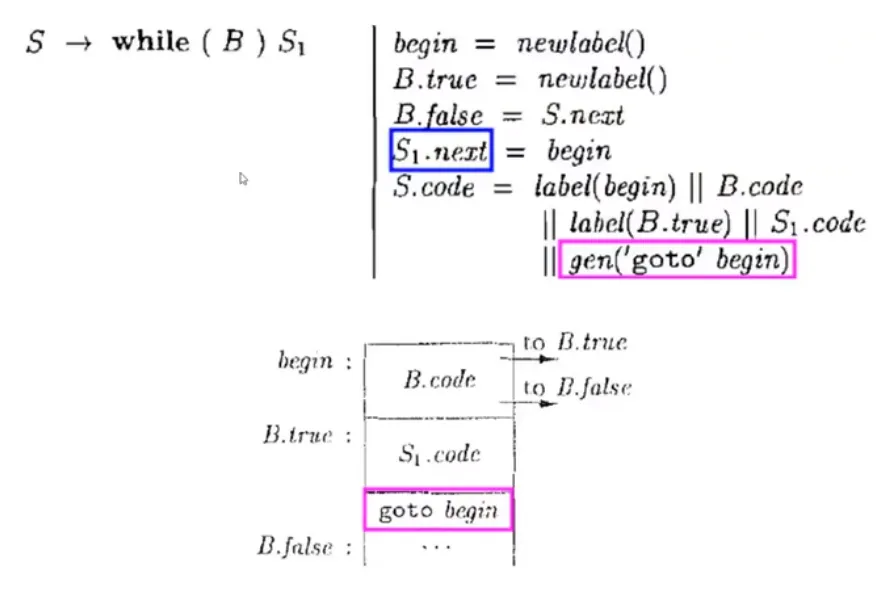
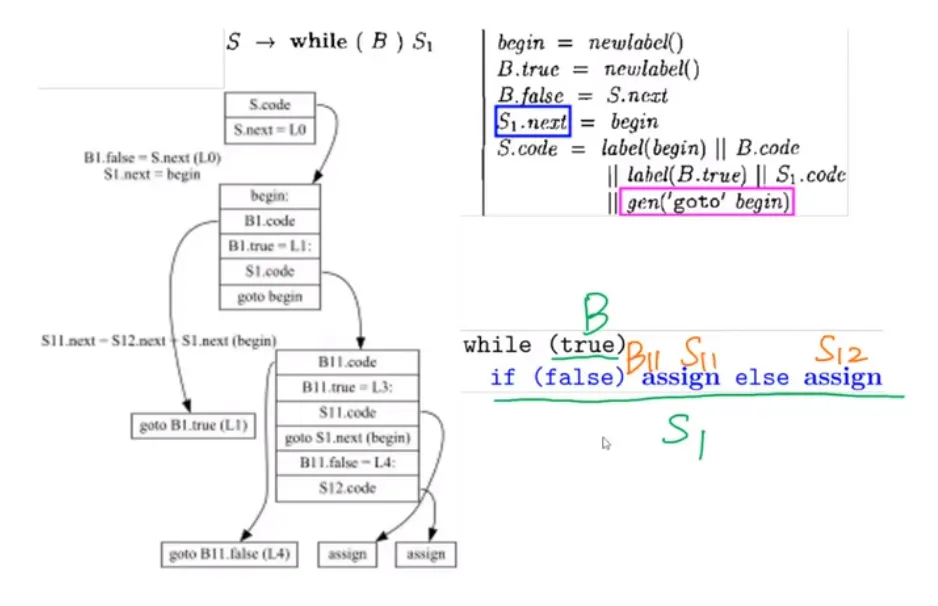
最终生成的 IR code:
1 | begin: |
并列顺序语句:

布尔表达式:



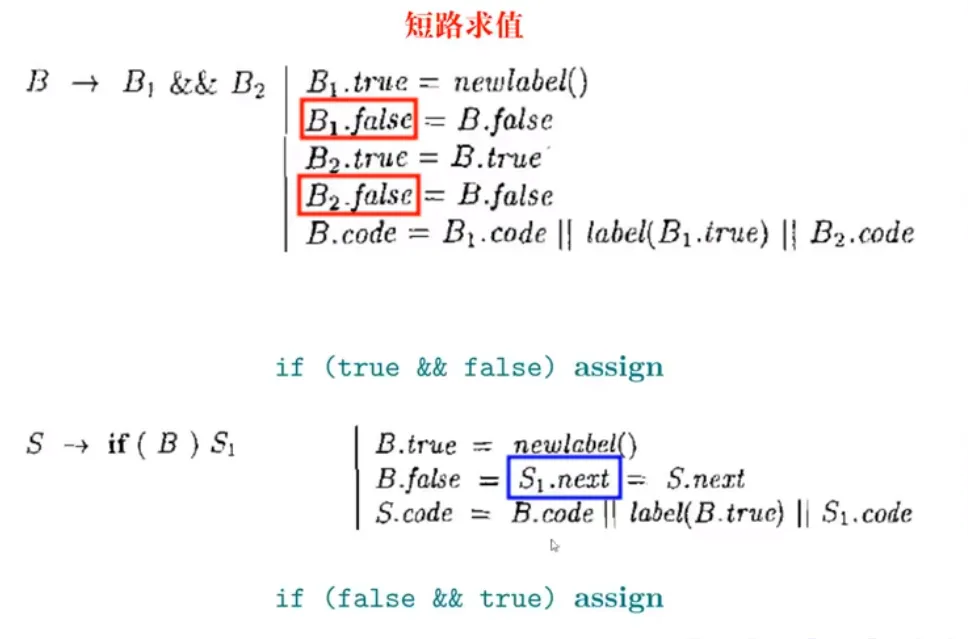
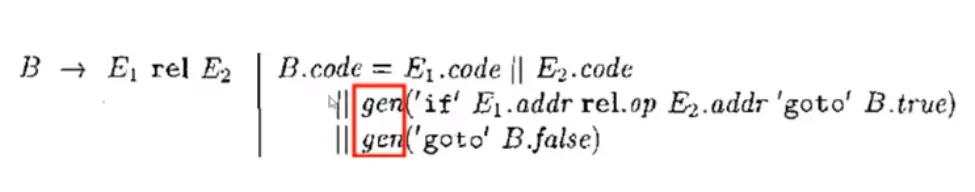
一个复杂的例子:
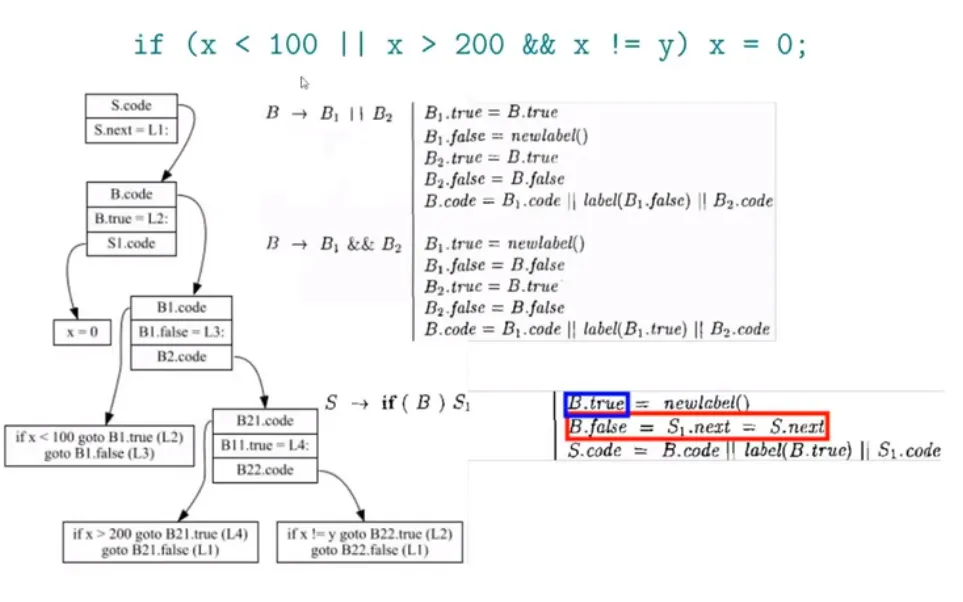
最终生成的 IR code:
1 | if x < 100 goto L2 |
生成 LLVM IR code 并可视化展示控制流图

使用 ANTLR v4 生成控制流
参考样例代码:
关于布尔表达式的补充

