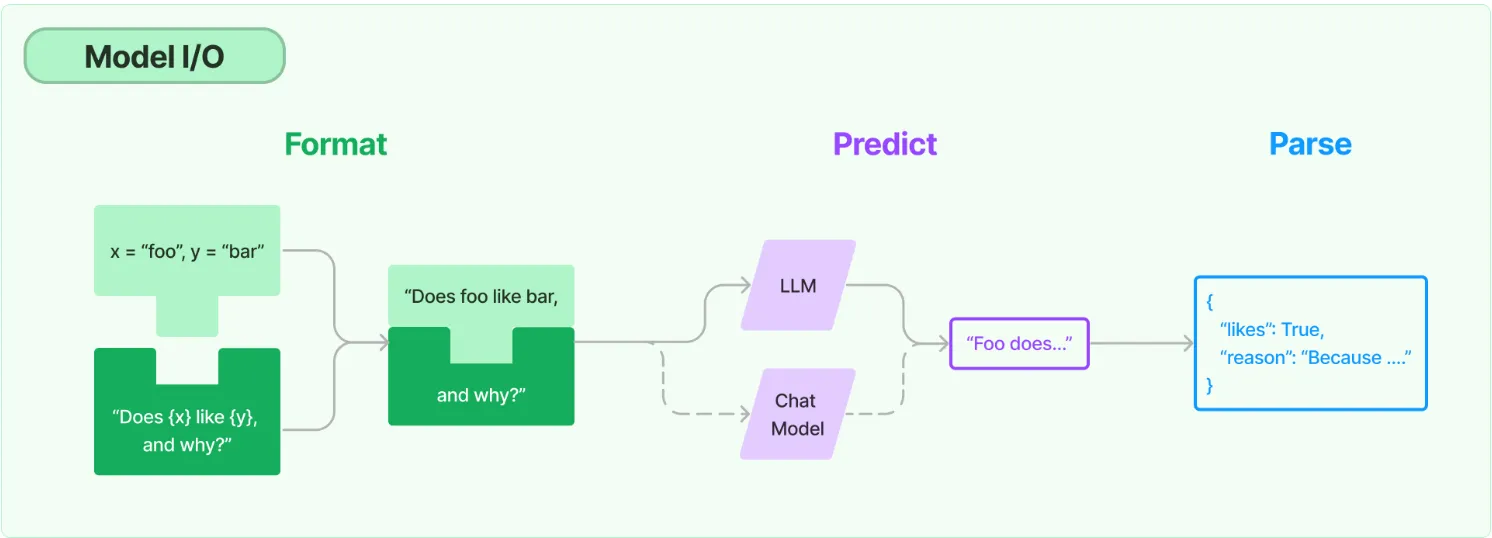
# create a example template example_template = "User: {query}\nAI: {answer}“ # create a prompt example from above template example_prompt = PromptTemplate( input_variables=["query", "answer"], template=example_template ) # now break our previous prompt into a prefix and suffix # the prefix is our instructions prefix = """The following are excerpts from conversations with an AI assistant. The assistant is typically sarcastic and witty, producing creative and funny responses to the users questions. Here are some examples: """ # and the suffix our user input and output indicator suffix = "User: {query}\nAI: " # now create the few shot prompt template few_shot_prompt_template = FewShotPromptTemplate( examples=examples, example_prompt=example_prompt, prefix=prefix, suffix=suffix, input_variables=["query"], example_separator="\n\n" ) prompt= few_shot_prompt_template.format(query="What is the meaning of life?")
在 examples 数量较多的情况下,动态地选择和构造 few-shot prompt
基于长度:可以限制过多的标记使用,并避免超出 LLM 的最大上下文窗口而导致错误
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from langchain.prompts.example_selector import LengthBasedExampleSelector
example_selector = LengthBasedExampleSelector( examples=examples, example_prompt=example_prompt, max_length=50# this sets the max length that examples should be )
dynamic_prompt_template = FewShotPromptTemplate( example_selector = example_selector, # use example_selector instead of examples example_prompt=example_prompt, prefix=prefix, suffix=suffix, input_variables=["query"], example_separator="\n\n" )
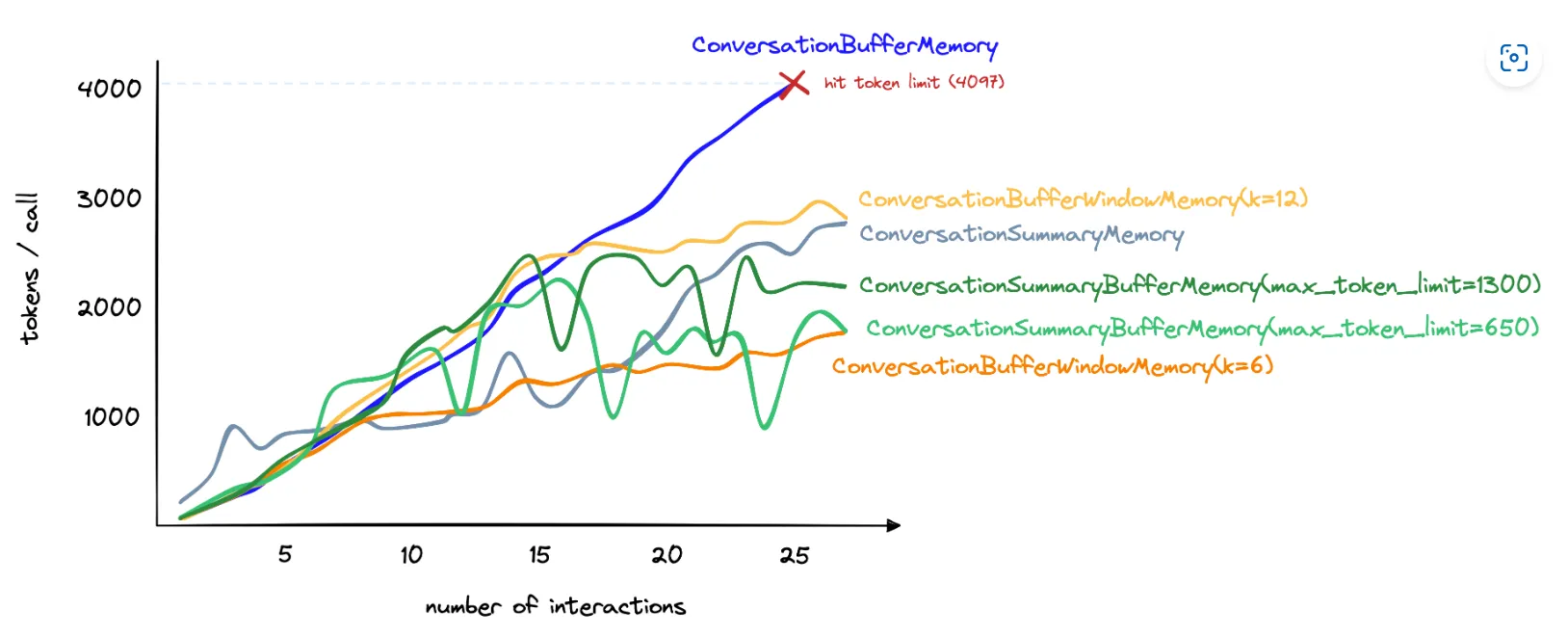
二、会话记忆 - Conversational Memory
便捷地管理和组织连续对话的上下文:
帮助无状态的 LLM 以类似于有状态的环境的方式进行交互,能够考虑并参考过去的交互
可以实现自己的记忆模块,在同一链中使用多种类型的记忆,将它们与代理结合使用等等
使用 ConversationChain 来管理 LLM 的会话记忆
1 2 3 4 5 6 7 8 9 10 11 12
from langchain import OpenAI from langchain.chains import ConversationChain
# first initialize the large language model llm = OpenAI( temperature=0, openai_api_key=os.getenv('OPENAI_API_KEY'), model_name="text-davinci-003" )
# now initialize the conversation chain conversation = ConversationChain(llm=llm)
conversation.prompt.template 中包含了 {history} 和 {input} 两个参数,其中 history 是使用对话记忆的地方,input 是放置最新的人类查询的地方。
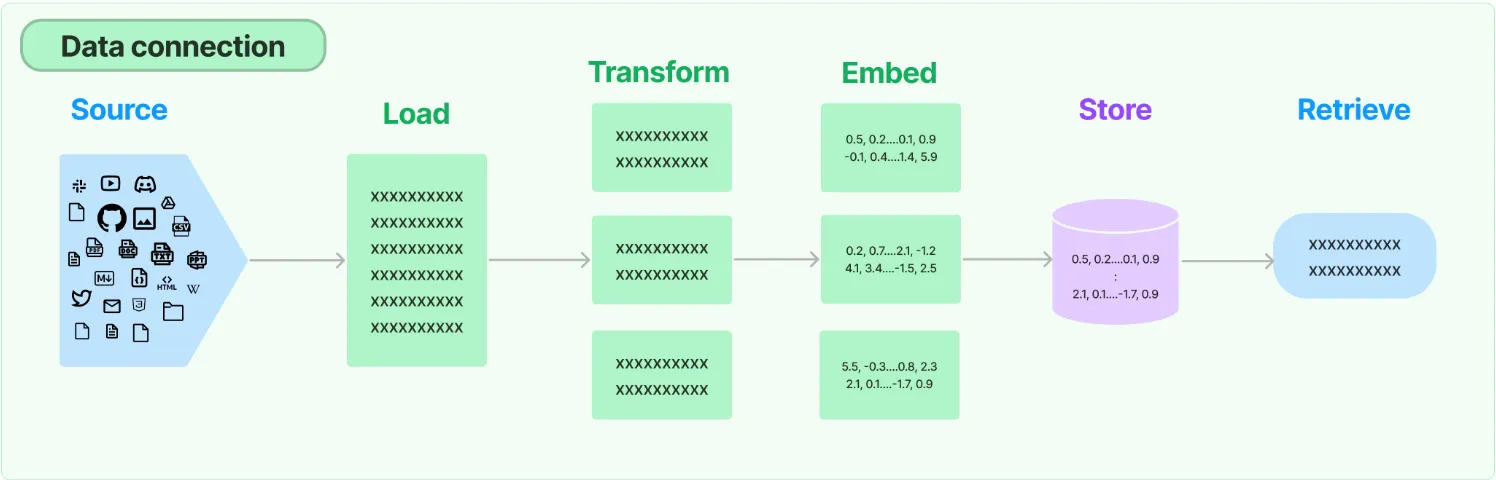
for i, record inenumerate(tqdm(data)): # get metadata fields for this record metadata = { 'wiki-id': str(record['id']), 'source': record['url'], 'title': record['title'] } # create chunks from the record text record_texts = text_splitter.split_text(record['text']) # create individual metadata dicts for each chunk record_metadatas = [{ "chunk": j, "text": text, **metadata } for j, text inenumerate(record_texts)] # append these to current batches texts.extend(record_texts) metadatas.extend(record_metadatas) # if we have reached the batch_limit we can add texts iflen(texts) >= batch_limit: ids = [str(uuid4()) for _ inrange(len(texts))] embeds = embed.embed_documents(texts) Index.upsert(vectors=zip(ids, embeds, metadatas)) texts = [] metadatas = []
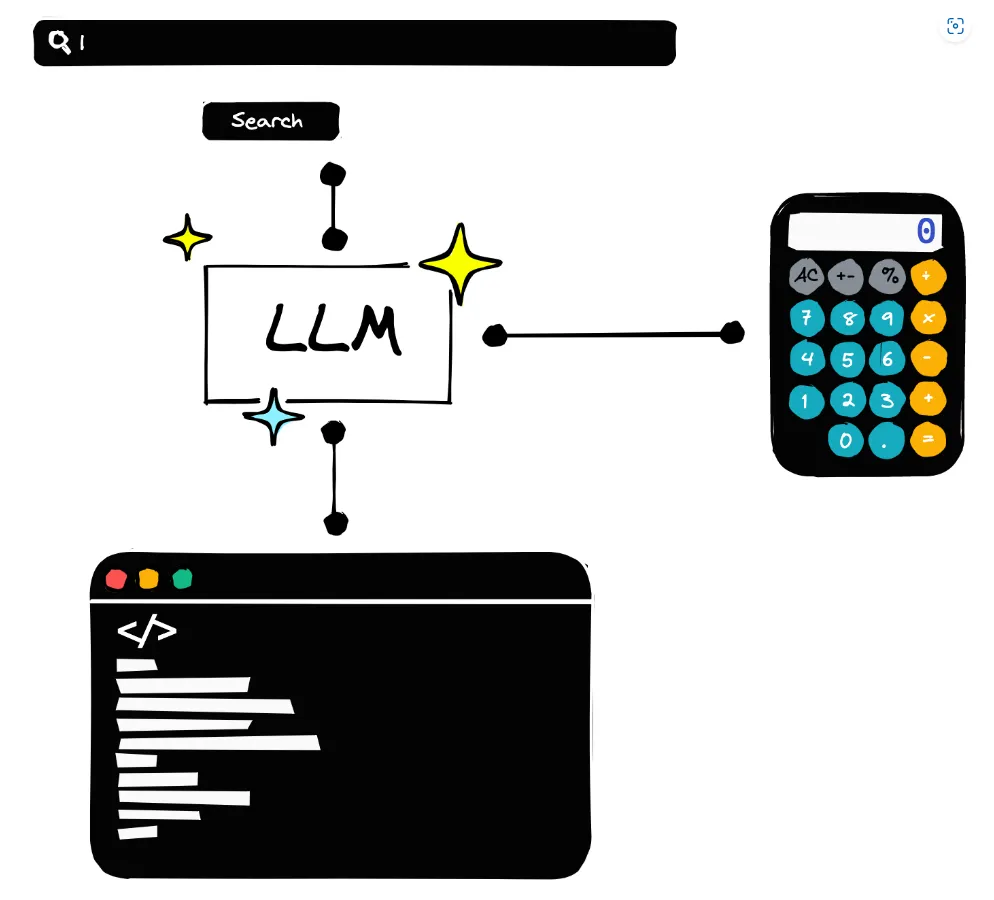
"""Tool(s) to be interacted""" from langchain.chains import LLMMathChain from langchain.agents import Tool
llm_math = LLMMathChain(llm=llm) # initialize the math tool math_tool = Tool( name='Calculator', func=llm_math.run, description='Useful for when you need to answer questions about math.' ) llm_tool = Tool( name ='Language Model', func = llm_chain.run, description ='use this tool for general purpose queries and logic' ) # when giving tools to LLM, we must pass as list of tools tools = [math_tool, llm_tool] # directly load pre-constructed tools # from langchain.agents import load_tools # tools = load_tools(['llm-math'], llm=llm)
"""Agent""" from langchain.agents import initialize_agent
self_ask_with_search("who lived longer; Plato, Socrates, or Aristotle?")
五、自定义工具 - Custom Tools
简单的订制工具
以一个简单的计算圆周长的工具为例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
from langchain.tools import BaseTool # Necessary template of LangChain tools from math import pi from typing importUnion classCircumferenceTool(BaseTool): # Necessary attribute of a LangChain tool self.name = "Circumference calculator" self.description = "use this tool when you need to calculate a circumference using the radius of a circle"
# Asynchronous call def_arun(self, radius: int): raise NotImplementedError("This tool does not support async")
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
from langchain.chat_models import ChatOpenAI from langchain.chains.conversation.memory import ConversationBufferWindowMemory
# initialize LLM (we use ChatOpenAI because we'll later define a `chat` agent) llm = ChatOpenAI( openai_api_key=os.getenv("OPENAI_API_KEY"), temperature=0, model_name='gpt-3.5-turbo' )
sys_msg = """Assistant is a large language model trained by OpenAI. Assistant is designed to be able to assist with a wide range of tasks, from answering simple questions to providing in-depth explanations and discussions on a wide range of topics. As a language model, Assistant is able to generate human-like text based on the input it receives, allowing it to engage in natural-sounding conversations and provide responses that are coherent and relevant to the topic at hand. Assistant is constantly learning and improving, and its capabilities are constantly evolving. It is able to process and understand large amounts of text, and can use this knowledge to provide accurate and informative responses to a wide range of questions. Additionally, Assistant is able to generate its own text based on the input it receives, allowing it to engage in discussions and provide explanations and descriptions on a wide range of topics. Unfortunately, Assistant is terrible at maths. When provided with math questions, no matter how simple, assistant always refers to it's trusty tools and absolutely does NOT try to answer math questions by itself Overall, Assistant is a powerful system that can help with a wide range of tasks and provide valuable insights and information on a wide range of topics. Whether you need help with a specific question or just want to have a conversation about a particular topic, Assistant is here to assist. """
from typing importOptional from math import sqrt, cos, sin
desc = ( "use this tool when you need to calculate the length of a hypotenuse" "given one or two sides of a triangle and/or an angle (in degrees). " "To use the tool, you must provide at least two of the following parameters " "['adjacent_side', 'opposite_side', 'angle']." ) # Teach LLM about input format / requirement
classPythagorasTool(BaseTool): self.name = "Hypotenuse calculator" self.description = desc def_run( self, adjacent_side: Optional[Union[int, float]] = None, opposite_side: Optional[Union[int, float]] = None, angle: Optional[Union[int, float]] = None ): # check for the values we have been given if adjacent_side and opposite_side: return sqrt(float(adjacent_side)**2 + float(opposite_side)**2) elif adjacent_side and angle: return adjacent_side / cos(float(angle)) elif opposite_side and angle: return opposite_side / sin(float(angle)) else: return"Could not calculate the hypotenuse of the triangle. Need two or more of `adjacent_side`, `opposite_side`, or `angle`." def_arun(self, query: str): raise NotImplementedError("This tool does not support async")